By Joel Kline | STC Senior Member and Frank Guerino
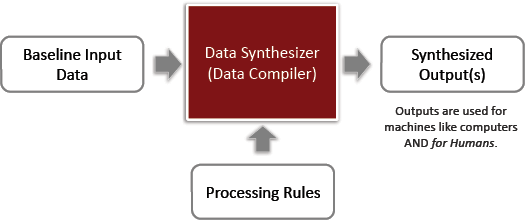
Introduction to Data-Driven Synthesis (DDS)
Most technical communication (TC) practitioners are familiar with content authoring tools that generate, curate, and publish content one page at a time, such as content management systems (CMSs) and wikis. Most of us are also familiar with software compilers that convert software source code into executable software that can be installed and run on computers (e.g., Java and C++ compilers). This article is about a rapidly evolving paradigm called Data-Driven Synthesis (DDS). Like software compilers, DDS uses tools we call data compilers to ingest data and automatically generate very large volumes of content which could not otherwise be written by human hands without significant time, effort, and funds.
Consider, for example, being assigned 1,000 products that you have to fully document across your company’s website, intranet, and product literature. Imagine requiring at least one page per product. Next, imagine the work of creating all 1,000+ pages, formatting them, creating catalog pages, creating indices, and maintaining all the links for all these product pages. Even if you use a database-driven solution, you still encounter challenges when the data structure changes, such as when each product gets a Twitter handle.
DDS is a paradigm that allows TC practitioners to author content faster, with much higher levels of quality, and for a fraction of the costs.
Synthesis is not new
Synthesis, as a general concept, is not new. Compilation of computer source code, for the purpose of generating executable computing constructs (i.e., software), dates back to the 1950s. Synthesis of semiconductor simulation, emulation, and fabrication constructs from 4GL languages such as VHDL and Verilog has been the norm since the mid-1990s.
More recent examples of synthesis can be found in solutions such as software scaffolding frameworks like Ruby on Rails, in big data analytics, in visualization generation solutions like Data-Driven Documents (D3.js), and in predictive analytics solutions that help automatically calculate things like healthcare pathways for patient treatments and pharmaceutical drugs for targeted clinical outcomes.
DDS works for both tiny data and big data
Data scientists commonly use DDS to automatically perform complex informatics work that involves looking for patterns and anomalies in very large sets of big data (often many petabytes). Many TC practitioners often deal with much smaller data sets that are usually no bigger than gigabytes, often referred to as tiny data. In our example of managing 1,000 products, the amount of data is small compared to big data, but the challenges lie in publishing and updating.
The Wikipedia Problem
Technical communicators have used wikis for content generation since the advent of Web 2.0. While the value of wikis for collaborative writing is undisputed, their use for content generation within the enterprise produces numerous challenges. Enterprises often cite Wikipedia as the example for how to decentralize content generation and provide everyone with a role in creating content. However, this decentralized model of content generation rarely—even with oversight from technical communicators—yields the volume and quality of content necessary for success.
Let’s briefly examine why a Wikipedia paradigm for enterprise content generation is problematic. The primary problem with Wikipedia for enterprise authoring is its Long Form Notation (LFN) structure. This leads to many authoring problems. One such problem is scale. It takes many people long periods of time to write content for wikis. Most enterprises have a difficult, if not impossible, time getting employees to write wiki entries. A second problem with wikis is indexing. LFN makes it hard to index the content and difficult to create relationships between data and its attributes. A third problem with wiki content is repurposing. LFN makes Wiki content difficult to automatically repurpose because of the absence of data attributes. The final problem with wiki content is updating. Although the hyperlinked structure makes link updates easy, the LFN in a wiki makes it challenging to locate and update individual data elements.
The paradigm of Data-Driven Synthesis uses automated content generation to solve the problems presented by the Wikipedia paradigm. DDS methods use your data to create very large volumes of high quality content, quickly. In this article, we show how one dynamic compiler converts anything in a Comma Separated Value (CSV) format to HTML documentation to display different knowledge constructs and dependencies to your audience using Short Form Notation (SFN). SFN eliminates long verbose paragraphs that are associated with LFN by replacing them with sets of succinct name-value data pairs. With simple data management constructs like spreadsheets or other flat files, DDS data compilers use these name-value pairs to format and connect data. The compilation feature for DDS is one of the paradigm’s major strengths. When data changes, just recompile and republish. This makes it easy to quickly change and repurpose large volumes of content.
If data-driven synthesis can solve your automatic content generation problems, what’s holding you back? In the next section, we present a short argument for learning to employ dynamic data-driven synthesis for content generation in your enterprise.
DDS Bridges Technical Communication and Big Data
You cannot read a current periodical in the fields of business, information science, or communication without seeing the term big data. Big data and its discipline, data science, is an important concept for technical communicators who generate content. But not all topics related to data science are central to technical communication. In fact, tiny data is more relevant to TC professionals than big data. Most TC practitioners will not be accessing petabytes of data in order to generate content. Instead, they commonly deal in data sets that are hundreds to thousands of records per topic area (e.g., our recurring example of 1,000 products with 100 descriptive traits). This is far less complex, for example, than business intelligence activities that require analysis of millions of daily transactions. However, big data methods can be useful to TC professionals, even when working in tiny data spaces. Big data methods can facilitate the automatic generation of large quantities of higher quality content, such as richly formatted views of content and different knowledge constructs that include data visualizations. As noted earlier, DDS paradigms can overcome Wikipedia paradigm problems associated with LFN such as scaling, indexing, repurposing, and updating. An additional benefit to the DDS paradigm is the ability to synthesize data visualizations so that technical communicators do not have to write code to create a visualization.
DDS provides an entry point for technical communicators to harness the power of data visualization. When content is in a dynamic format, it is possible to output to numerous kinds of data visualization schemas. Data visualization occurs when the synthesizer (i.e., data compiler) discovers data attributes, data formats, and data relationships via rules specified by the TC practitioner generating the outputs. DDS-generated data is typically structured as Short Form Notation that contains a name-value data pair (i.e., a descriptive attribute and its data value). Consider our 1,000 products example. DDS permits the technical communicator to combine product data with other enterprise data to easily generate visualizations that tell stories about the products. For example, visualizations can be generated that show relationships between products and other important data entities, such as people, documents, organizations, videos, and images.
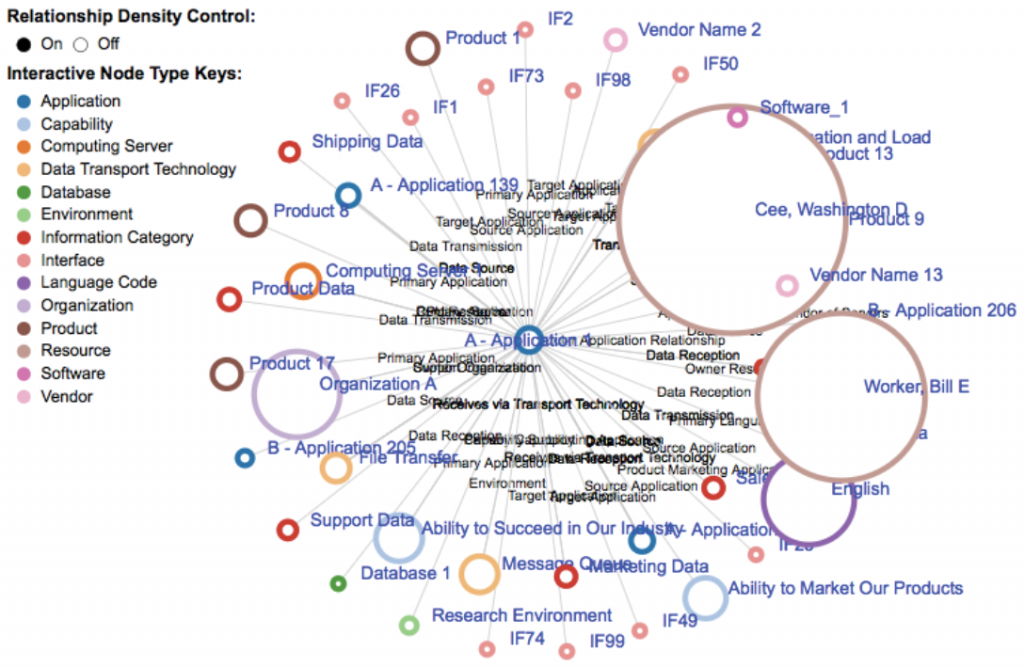
In a DDS system, a technical communicator can compile CSV flat files to produce visualizations that represent the many different things which are related to each product. For example, your enterprise may have different support documents, videos, links, images, and people associated with specific products. The data compiler generates content that helps visualize different traits for each product instance. In Figure 2, the data compiler generated visual relationships between a product and other things it is related to (e.g., applications, contracts, other products, human resources, etc.).
Incorporation of DDS paradigms is critical for making the transition from static documentation to dynamic documentation. This change requires that the technical communicator identify relationships between data and its attributes. However, once those relationships are identified, the compiler now has the capacity to generate all kinds of dynamic output, including vast quantities of richly formatted content, various knowledge constructs, and bundled package sets like digital libraries. Our next section describes the application of DDS Synthesis to these specific areas.
How to Use DDS for Technical Communication
We’ve found that applying DDS to automatically generate electronic documentation has direct and positive impacts on the productivity of TC professionals. Tools like the IF4IT NOUNZ Data Compiler use DDS to automatically generate interactive electronic documentation, thus empowering a single person to outperform large human labor forces. Data compilers ingest structured data and use processing rules to produce at least three key outputs that are useful for TC practitioners:
- Large volumes of richly formatted content.
- Knowledge constructs, including data visualizations.
- Digital libraries.
Synthesis of large volumes of richly formatted content
Let’s return to our example of authoring content in support of 1,000 products. Traditionally, there were only two options for building consistent and accurate Web pages for these products. The first option was to leverage tools that allow human labor forces to create and format each page, one at a time (e.g., content management systems). The second option was to build custom software solutions.
The first option requires lower levels of skill but is limited by the performance of humans. It is slow and prone to significant human error. The second option requires complex skills to design, deliver, and maintain the custom system. Both options are expensive and are tied to long delivery times.
DDS based solutions offer a third option. Data compilers like NOUNZ allow a TC professional to easily submit their data to the compiler and automatically generate electronic documentation views with little effort and with just a few minutes of work (see Figure 3).
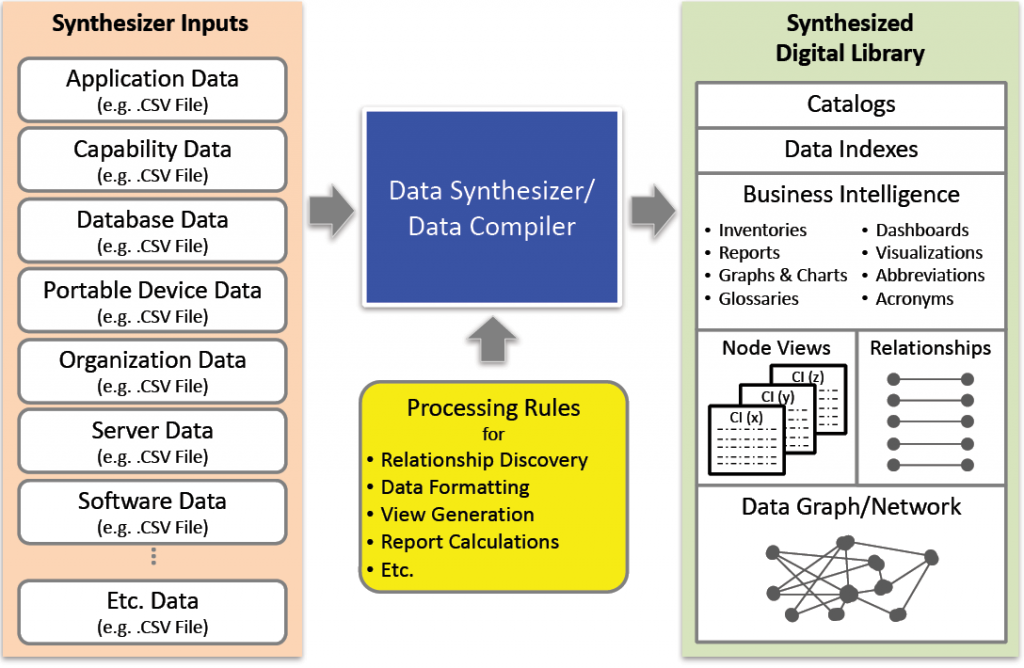
In authoring content to support 1,000 products, the technical communicator would submit product data as CSV flat files to a data compiler that would automatically create more than just 1,000 individual product pages of content. In addition to creating descriptive content pages that mostly use text, the data compiler can also generate interactive data visualization views that highlight and compare data relationships between products and other important data types. A data compiler can easily generate many different views that humans would otherwise not have the time or funding to create manually or via custom application development. Data compilers also ensure that pages are consistently formatted so that the user experience makes it easier to explore, discover, and learn.
Synthesis of knowledge constructs (KCs) such as data visualizations
In addition to the generation of many content pages, DDS-based data compilers also generate both simple and complex knowledge constructs (KCs). KCs are interactive structures that facilitate stronger knowledge management. In other words, they help end users more effectively and efficiently explore, discover, learn, and understand. Examples of KCs include but are not limited to navigation and classification taxonomies, library catalogs and indexes, simple charts and graphs, semantic data graphs and relationships, sortable lists and tables, reports, interactive dashboards, and complex data visualizations (see Figure 4).
The reader will note that, even with tens of millions of contributors, Wikipedia has very few consistent knowledge constructs and almost none of them are driven by data. In Wikipedia, this means that knowledge structures do not change when data changes, thus requiring human labor to address such changes. For example, list and table structures exist but are formatted differently, from topic to topic. Charts and graphs are inconsistent static images that are first generated in other tools, exported to stand-alone files, uploaded into Wikipedia, and then linked into page content as references to files that cannot change as the data changes below them. This means that the effort necessary to create and manage such knowledge constructs, especially as data changes, is far too great, even for the vast Wikipedia community. On the other hand, data compilers make this type of work easy, quick, and very consistent.

Data compilers allow technical communicators to generate millions of charts, graphs, dashboards, and interactive data visualizations, with nothing more than a few commands that tell the compiler how to handle and format your data. More importantly, data compilers make it very easy to update all the knowledge constructs when data changes. This means that maintaining and changing millions of charts, graphs, dashboards, and interactive data visualizations becomes much simpler work. It also translates to a very powerful exploration, discovery, and learning experiences for TC end users.
Synthesis of highly curated digital libraries for technical communication
Most technical communicators who work with complex documentation understand the complexities associated with structure development. For example, it takes significant effort to manage document branding, page headers and footers, page sequencing, chapter structuring, bibliographies, index design, figure placements, table of contents generation, etc. All too often, content management websites like enterprise intranets have very little long-term planning and design that go beyond basic layout templates and consistent color schemes. Wikipedia, a far larger and more complex example, had almost no formal planning and design, making it virtually impossible to replicate via manual effort. This is where data compilers that leverage DDS can be very powerful tools for technical communicators.
In addition to automatically generating very large volumes of digital content pages and many different knowledge constructs, data compilers will also perform the work of weaving them all together into consistent and brand-able digital documentation packages that can be deployed to people and systems. This weaving occurs via the automatic generation of vast numbers of HTML links, each with specific structural intent, that facilitate navigation within and across data, content pages, and knowledge structures.
The importance of HTML link generation and maintenance should not be taken lightly. Wikipedia has so many HTML links that many millions of them are considered to be dead links, in spite of having tens of millions of content contributors. The problem manifests itself when underlying data or content changes and documenters must return to identify and update HTML links that are impacted because of the changes. If Wikipedia cannot properly address this problem with manual labor, even with tens of millions of editors, how can a small team of technical communicators address such impacts in their own electronic documentation?
Software like Wikimedia’s Wiki, Adobe Technical Communication Suite, and MadCap Flare all provide features that help technical communicators define and build their document structures and sets. Data-driven synthesis tools go a few steps further in that they automatically create vast numbers of dynamic HTML links and use these links to assemble large documentation packages. The NOUNZ data compiler, for example, specifically generates portable electronic documentation packages that are called digital libraries, which can easily consist of millions of HTML links (see Figure 5). These digital libraries are deployable websites that follow the structural navigation, storage, and access patterns of traditional brick-and-mortar libraries. If underlying data changes, technical communicators can simply recompile the entire library with very little effort.

The paradigm of DDS even makes it easy for technical communicators to create multiple digital libraries (i.e., different topic instances) for federated topic management and to manage historical versions, since each compiled output is treated as a separate snapshot in time. And, because the outputs of compilers like NOUNZ can also be represented as Semantic Data Graphs (SDGs), technical communicators can even store them to NoSQL repositories for big data analytics.
DDS Adoption Considerations
Working with data-driven synthesis tools can be very productive for technical communicators. However, doing so requires some new ways of thinking and acting. The first thing to consider is that your focus for documentation and publication will shift from developing raw and unstructured content, in Long Form Notation (LFN), to highly structured Name-Value pair content, using Short Form Notation (SFN). This means the bulk of your content will be driven from data and that you will need to spend more time collecting and preparing data than you would on writing narratives.
Another important consideration is your shift in required skills and in how content is authored. With traditional content management systems like Wikis, you can have non-technical people in your end user audience create and publish their own articles, even if curating them becomes difficult. Shifting to DDS means that one person or a small team of people who know how to install, set up, and run data compilers will have responsibilities for the bulk of content creation and curation. End users who want to create content will have to submit their materials to you for integration and curation with the data compiler. For example, others may write policy documents but they will have to hand them off to you for integration into the policy data inventories that you use to feed the data compiler. The upside is that one person using the DDS paradigm with a data compiler will often significantly outperform an army of people who are manually generating content.
Finally, technical communicators must get used to a constant recompilation of content with DDS data compilers. Using traditional CMSs, people submit content and rarely go back to update it (or do so far less than they should). Using DDS and data compilers means that changes in data cause the compiler to update any and all other data and content that is affected by such changes. The upside is that doing so is easy and quick. This allows you to iteratively improve your data and your content, quickly seeing the impacts of your changes with every new compilation. Prepare for some of these changes as you begin to experiment with DDS methods and models.
Conclusion
The data-driven synthesis paradigm is a different way of thinking about and working with your content. Traditional content management paradigms, such as Wikipedia, have popularized the idea that “everyone is an author” and can publish content in your enterprise. This often results in issues with updating and repurposing content, issues with Long Form Notation (LFN), and poorly curated content. DDS is a paradigm that overcomes many of these issues.
The paradigm of synthesis is not new and has been leveraged for decades in many industries for many different reasons. Specifically, DDS for rapid and automatic generation of content is evolving as a critical means for technical communicators to work more efficiently and effectively. In this article we’ve shown TC practitioners how they can use DDS and data compilers to automatically create large volumes of richly formatted content, synthesize many different knowledge constructs, and generate fully branded and assembled digital libraries.
Choosing to work with DDS tools comes with different tradeoffs that every technical communicator should be aware of. However, the benefits are significant and offer the technical communicator a pathway to faster and higher quality content generation, at lower costs.
JOEL A. KLINE (https://www.linkedin.com/in/drjoelkline), PhD, APR, is a Professor of digital communications at Lebanon Valley College. Joel teaches courses in technology strategy, e-commerce, and entrepreneurship. He is the treasurer of the International Digital Media Arts Association and accredited in public relations by the Public Relations Society of America. Prior to entering academia, he was a principal at a boutique agency and worked in B2B communication in the private sector. Joel consults and researches in the areas of knowledge management, entrepreneurship, and user experience.
FRANK GUERINO (https://www.linkedin.com/in/frankguerino) is an expert in areas of semantic data theory and Data-Driven Synthesis (DDS). He specializes in the design and application of semantic data compilers that use these paradigms to solve complex knowledge management problem. He currently serves as the chairman for the International Foundation for Information Technology (IF4IT) (www.if4it.com), where he helps publish IT industry best practices and helps educate and certify IT professionals. In addition to his current role, Frank has spent almost 30 years as a technologist, leader, and advisor in the semiconductor, financial, pharmaceutical, healthcare, insurance, and government contracting industries.

