By Jeff Johnson
Reading is a complex, taxing process, particularly for unskilled readers. While speaking and understanding spoken language is a natural human ability, reading is not. Technical communicators can increase reading speed and comprehension with careful, science-based design.
This article is an abridged excerpt from the book Designing with the Mind in Mind: Simple Guide to Understanding User Interface Guidelines, Third Edition. Some explanations and examples have been removed due to space constraints.
Most people in industrialized nations grow up in households and school districts that promote education and reading. They learn to read as young children and become good readers by adolescence. As adults, most of our activities during a normal day involve reading. Reading is, for most educated adults, automatic, leaving our conscious minds free to ponder the meaning and implications of what we are reading. Because of this background, it is common for good readers to consider reading a “natural” human activity, like speaking.
We Are Wired for Language but Not for Reading
Speaking and understanding spoken language is a natural human ability, but reading is not. Over hundreds of thousands — perhaps millions — of years, the human brain evolved the neural structures necessary to support spoken language. Humans are born with an innate ability to learn, with no systematic training, whatever language they are exposed to. After early childhood, this ability decreases significantly. For example, newborn babies can hear and distinguish all the sounds of all languages, but as they learn the language of their home environment, they lose the ability to distinguish sounds that are not distinguished in that language.1 By adolescence, learning a new language is the same as learning any other skill — it requires instruction and practice, and the learning and processing are handled by different brain areas from those that handled it in early childhood.2
In contrast, writing and reading did not exist until a few thousand years BCE and did not become commonplace until only four or five centuries ago — long after the human brain had evolved into its modern state. At no time during childhood do our brains show any special innate ability to learn to read. Instead, reading is an artificial skill that we learn by systematic instruction and practice, like playing a violin, juggling, or reading music.2
Many People Never Learn to Read Well, or at All
Because people are not innately “wired” to learn to read, children who either lack caregivers who read to them or receive inadequate reading instruction in school may never learn to read. There are a great many such people, especially in the developing world. By comparison, very few people never learn a spoken language. Some people who do learn to read never become good at it.
A person’s ability to read is specific to a language and script (a system of writing). To see what text looks like to someone who cannot read, look at a paragraph printed in a language and script that you do not know (Figure 1).

Alternatively, you can approximate the feeling of illiteracy by taking a page written in a familiar script and language and turning it upside down. Turn this magazine upside down and try reading the next few paragraphs. This exercise only approximates the feeling of illiteracy. You will discover that the inverted text appears foreign and illegible at first, but after a minute you will be able to read it, albeit slowly and laboriously.
Learning to Read Equals Training Our Visual System
Learning to read involves training our visual system to recognize patterns exhibited by text.
 These patterns run the gamut from low-level to high-level:
These patterns run the gamut from low-level to high-level:
- Lines, contours, and shapes are basic visual features that our brain recognizes innately. We don’t have to learn to recognize them.
- Basic features combine to form patterns that we learn to identify as characters — letters, numeric digits, and other standard symbols. In ideographic scripts, such as Chinese, symbols represent entire words or concepts.
- In alphabetic scripts, patterns of characters form “morphemes,” which we learn to recognize as packets of meaning — for example, “farm,” “tax,” “-ed,” and “-ing” are morphemes in English.
- Morphemes combine to form patterns that we recognize as words — for example, “farm,” “tax,” “-ed,” and “-ing” can be combined to form the words “farm,” “farmed,” “farming,” “tax,” “taxed,” and “taxing.”
- Words combine to form patterns that we learn to recognize as phrases, idiomatic expressions, and sentences.
- Sentences combine to form paragraphs.
How We Read
Assuming our visual system and brain have successfully been trained, reading becomes semiautomatic or fully automatic — both eye movement and processing.
As we read, our eyes constantly jump around, several times a second. Each of these movements, called “saccades,” lasts about 0.1 second. Saccades are ballistic, like firing a shell from a cannon. Their endpoint is determined when they are triggered, and once triggered, they always execute to completion. The destinations of saccadic eye movements are programmed by the brain from a combination of our goals, events in the visual periphery, and events detected and localized by other perceptual senses and past history, such as training.
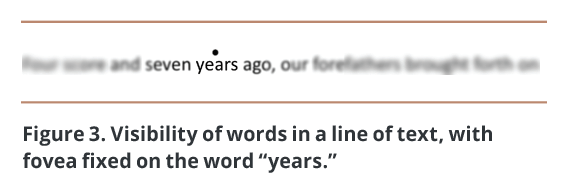
When we read, we may feel that our eyes scan smoothly across the lines of text, but that feeling is incorrect. In reality, our eyes continue with saccades during reading, but the movements generally follow the line of text. They fix our “fovea” — a small area in the retina that allows us to see high-resolution detail in the center of our visual field — on a word, pause there for a fraction of a second to allow basic patterns to be captured and transmitted to the brain for further analysis, then jump to the next important word.3 Eye fixations while reading always land on words, usually near the center and not on word boundaries (Figure 2). Very common small connector and function words like “a,” “and,” “the,” “or,” “is,” and “but” are usually skipped over, their presence either detected in perifoveal vision — within the small area immediately surrounding the fovea — or simply assumed. Most of the saccades during reading are in the text’s normal reading direction, but a few, about 1 percent, jump backwards to previous words. At the end of each line of text, our eyes jump to where our brain guesses the next line begins.

How much can we take in during each eye fixation during reading? For reading European-language scripts at normal reading distances and text font sizes, the fovea clearly sees 3–4 characters on either side of the fixation point. The perifovea sees about 15-20 characters outside the fixation point, but not very clearly (Figure 3).
This is why centered text is difficult to read — it disrupts the brain’s guess about where the next line starts.
Due to how our visual system has been trained to read, perception around the fixation point is asymmetrical; it is more sensitive to characters in the reading direction than in the other direction. For European-language scripts, this is toward the right.
Is Reading Feature-Driven or Context-Driven?
Reading involves recognizing features and patterns. Pattern recognition, and therefore reading, can be either a bottom-up, feature-driven process, or a top-down, context-driven process.
In feature-driven reading, the visual system starts by identifying simple features — line segments in a certain orientation or curves of a certain radius — on a page or display and then combines them into more complex features, such as angles, multiple curves, shapes, and patterns. Then the brain recognizes certain shapes as characters or symbols representing letters, numbers, or for ideographic scripts, words. In alphabetic scripts, groups of letters are perceived as morphemes and words. In all types of scripts, sequences of words are parsed into phrases, sentences, and paragraphs that have meaning.
Feature-driven reading is sometimes referred to as “bottom-up” or “context-free.” The brain’s ability to recognize basic features — lines, edges, angles, etc. — is built in and therefore automatic from birth. In contrast, recognition of morphemes, words, and phrases has to be learned. It starts out as a nonautomatic, conscious process requiring conscious analysis of letters, morphemes, and words, but with enough practice it becomes automatic.2
Context-driven, or top-down, reading operates in parallel with feature-driven reading but works the opposite way, from whole sentences or the gist of a paragraph down to the words and characters. The visual system starts by recognizing high-level patterns like words, phrases, and sentences or by knowing the text’s meaning in advance. It then uses that knowledge to figure out, or guess, what the lower-level components of the high-level pattern must be.4 Context-driven reading is less likely to become fully automatic, because most phrase-level and sentence-level patterns and contexts don’t occur frequently enough to allow their recognition to become burned into neural firing patterns. But there are exceptions, such as idiomatic expressions.
To experience context-driven reading, glance quickly at Figure 4, then immediately direct your eyes back here and finish reading this paragraph. What did the text say?
Now look at the same sentence again more carefully. Do you read it the same way now? Also, based on what we have already read and our knowledge of the world, our brains can sometimes predict text — or its meaning — that the fovea has not yet read, allowing us to skip reading it. For example, if at the end of a page we read “It was a dark and stormy,” we would expect the first word on the next page to be “night.” We would be surprised if it was some other word like “cow.”

It has been known for decades that reading involves both feature-driven (bottom-up) and context-driven (top-down) processing. In addition to being able to figure out the meaning of a sentence by analyzing the letters and words in it, people can determine the words of a sentence by knowing the sentence’s meaning or the letters in a word by knowing what word it is (Figure 5). The question is: Is skilled reading primarily bottom-up or top-down, or is neither mode dominant?
Feature-Driven, Bottom-Up Reading Dominates; Context Assists
Reading consists mainly of context-free, bottom-up, feature-driven processes. In skilled readers, these processes are well-learned to the point of being automatic. Context-driven reading today is considered mainly a backup method that, although it operates in parallel with feature-based reading, is only relevant when feature-driven reading is difficult or insufficiently automatic.

Skilled readers may resort to context-based reading when feature-based reading is disrupted by poor presentation of information. In less-skilled readers, feature-based reading is not automatic; it is conscious and laborious. Therefore, more of their reading is context-based. Their involuntary use of context-based reading and nonautomatic, feature-based reading consumes short-term cognitive capacity, leaving little for comprehension. They have to focus on deciphering the stream of words, leaving no capacity for constructing the meaning of sentences and paragraphs. That is why poor readers can read a passage aloud but afterward have no idea what they just read.
Skilled and Unskilled Reading Use Different Areas of the Brain
Researchers have discovered that the neural pathways involved in reading differ for novice versus skilled readers. Of course, the first area to respond during reading is the occipital (or visual) cortex at the back of the brain. That is the same regardless of a person’s reading skill. After that, the pathways diverge.2
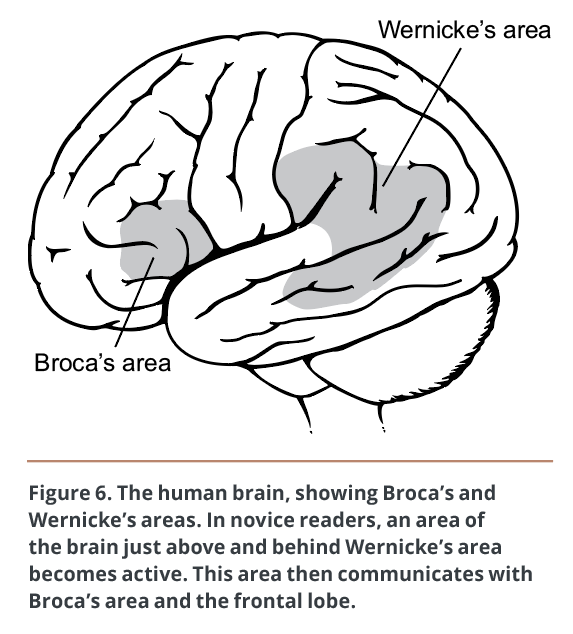
Novice
In novice readers, after the visual cortex is activated, an area of the brain just above and behind Wernicke’s area becomes active (Figure 6). Researchers have come to view this as the area where, at least with alphabetic scripts such as English and German, words are “sounded out” and assembled — that is, letters are analyzed and matched with their corresponding sounds. This word-analysis area then communicates with Broca’s area and the frontal lobe, where morphemes and words — units of meaning — are recognized and overall meaning is extracted. For ideographic languages, where symbols represent whole words and often have a graphical correspondence to their meaning, sounding out of words is not part of reading.
Advanced
In advanced readers, the word-analysis area is skipped. Instead, the occipitotemporal area (behind the ear, not far from the visual cortex) becomes active. The prevailing view is that this area recognizes words without sounding them out, then that activity activates pathways toward the front of the brain that correspond to the word’s meaning and mental image. Broca’s area is only slightly involved.
Poor Information Design Can Disrupt Reading
Careless writing or presentation of text can reduce skilled readers’ automatic, context-free reading to conscious, context-based reading, burdening working memory and thereby decreasing speed and comprehension. In unskilled readers, poor text presentation can block reading altogether. (Each of these concepts, as well as the design implications below, are explained in greater detail in the book, which also includes examples.)
Poor text presentation can take several forms, including the following:
- Uncommon or unfamiliar vocabulary
- Difficult scripts and typefaces
- Tiny fonts
- Text on noisy background
- Text contrasts poorly with background
- Information buried in repetition
- Centered text (or text aligned with a ragged start)
Design Implications
Information Developers can support both skilled and unskilled readers by following these guidelines:
- Avoid the disruptive flaws described earlier — difficult or tiny fonts, patterned backgrounds, centering, etc.
- Cut unnecessary text and minimize the need for reading.
- Use restricted, highly consistent vocabularies — sometimes referred to in the industry as “plain language” — or simplified language.5 (For more information about plain language, visit the U.S. government website, plainlanguage.gov.)
- Format text to create a visual hierarchy to facilitate easy scanning — use headings, bulleted lists, tables, and visually emphasized words.
- Test on real users. Designers should test their designs on the intended user population to be confident that users can read all essential text quickly and effortlessly.
 JEFF JOHNSON (jjohnson@uiwizards.com) is an Assistant Professor at the University of San Francisco Department of Computer Science. After earning degrees from Yale and Stanford Universities, Professor Johnson worked as a UI designer and implementer, engineer manager, usability tester, and researcher. He is a member of the Association for Computing Machinery (ACM) Special Interest Group on Computer-Human Interaction (SIGCHI) Academy and, in 2016, received SIGCHI’s Lifetime Achievement in Practice Award. He has authored and co-authored many publications on human-computer interaction, such as the books GUI Bloopers, Conceptual Models: Core to Good Design (with Austin Henderson), Designing User Interfaces for an Aging Population (with Kate Finn), and Designing with the Mind in Mind, now in its third edition.
JEFF JOHNSON (jjohnson@uiwizards.com) is an Assistant Professor at the University of San Francisco Department of Computer Science. After earning degrees from Yale and Stanford Universities, Professor Johnson worked as a UI designer and implementer, engineer manager, usability tester, and researcher. He is a member of the Association for Computing Machinery (ACM) Special Interest Group on Computer-Human Interaction (SIGCHI) Academy and, in 2016, received SIGCHI’s Lifetime Achievement in Practice Award. He has authored and co-authored many publications on human-computer interaction, such as the books GUI Bloopers, Conceptual Models: Core to Good Design (with Austin Henderson), Designing User Interfaces for an Aging Population (with Kate Finn), and Designing with the Mind in Mind, now in its third edition.
References
- Eagleman, David. 2015. The Brain: The Story of You. New York: Vintage Press
- Sousa, David A. 2005. How the Brain Learns to Read. Thousand Oaks: Corwin Press.
- Larson, Kevin. 2004. “The Science of Word Recognition.” Microsoft.com. http://www.microsoft.com/typography/ctfonts/WordRecognition.aspx.
- Boulton, David. 2009. “Cognitive Science: The Conceptual Components of Reading and What Reading Does for the Mind.” Filmed July 2004. Video, 5:57.
childrenofthecode.org/interviews/stanovich.htm. - Redish, Ginny. 2007. Letting Go of the Words: Writing Web Content that Works. San Francisco: Morgan Kaufmann.

