Abstract
Purpose: To describe the specification, procurement, and implementation of a new, XML-based technical documentation system for a large, multinational company.
Method: This study uses a descriptive analytical method, based on available project data, interviews, and fault analyses.
Results: The results of this research outline the technical, strategic, and organizational aspects that are associated with the procurement of a critical multi-site system where a high level of availability is necessary.
Conclusion: Organizational stakeholders were identified as critical for success; new authors' previous experiences lacked predictive value; existing documentation cultures at one specific site were not studied closely enough; and a deeper analysis of risk management with regard to the choice of DTD should have been made.
Keywords: XML, content management system, procurement, implementation, migration.
Practitioner's take-away:
- A futurological analysis is required to identify critical system features and functions.
- Considerable resources need to be spent on the development of an extensive request for quotation (RFQ). This step is crucial and will facilitate further analysis of tenders.
- A procurement can last several years, during which time some of the vendors may be restructured, which leads to them not being able to deliver.
- Data to be migrated can be disparate and can involve entirely different technical problems, risks, and solutions.
This case history describes a large multinational manufacturing company's second procurement of an XML-based documentation management system, their analysis of business needs, the development of the request for quotation (RFQ), and the solution that was eventually selected. Information is then provided about the migration of new and existing sites, and lessons learned from the procurement process and implementation of the system.
Background
In 2002, I procured an XML-based documentation system from the company Excosoft in order to ensure that the greatly expanded and highly dynamic product portfolio, which was then being established at the Swedish division of FLIR Systems (NASDAQ: FLIR), could be managed in a professional manner for the foreseeable future.
I presented that procurement, together with a description of the chosen system and a review of a number of technical aspects and solutions, in my article “A Successful Documentation Management System Using XML” (2004).
During the spring of 2012—10 years after that procurement—a new XML system was launched for the same division of the company, and that XML system is the subject of this article.
Company Development Since 2002
FLIR's revenue in 2002 was 261 million USD. Since then, the company has expanded greatly, both through a large number of acquisitions of other companies in related industries (13 acquisitions since 2007) and through the strategic identification of new applications, customer groups, and industrial segments. For 2014, the revenue was 1.5 billion USD.
Within the company, there is also a culture of continuous improvement and continual study of how costs can be cut, processes improved, and lead times reduced—a culture that undoubtedly has been highly significant in the context of revenue.
The Need for a New Documentation System
The Excosoft documentation system was in operation from December 2002 until the summer of 2012, and its strategic significance for FLIR's ability to be able to manage the steadily increasing volume of technical information cannot be overrated. Around 700 manuals were maintained actively in the system in 2012. Excosoft offered a very mature product and excellent technical support during phases that were often time-critical, and the company is still one of the most significant players when it comes to XML systems within the Nordic market.
In early 2007, I began a futurological study with the aim of identifying how technical information in a broader sense would need to be managed within the company in 5 years' time and which system requirements might be needed to cater for this. The great success of XML within the thermographic division had led other divisions and business units within the company to understand the advantages of this technology. In this context, it was, therefore, also relevant to take into account how new authors and authors unaccustomed to the technical aspects of XML could be offered a more efficient means of managing their documentation without being intimidated by the radically different way of working that XML entails compared with, e.g., Microsoft's Office package, Adobe InDesign, or Adobe FrameMaker. It was also important to find a good business model for a global project.
I identified, during this study, a number of user and functional aspects that I considered crucial both to attracting users who were new to and inexperienced in an XML-based workflow and also offering technically driven authors a very high level of advanced functionality and specialization. Added to this were a number of aspects that were not directly user-related but were considered critically important to the whole process flow, relative to the technical documentation.
During the spring of 2007, this study resulted in the development of a formal Request for Quotation.
Development of the Request for Quotation
The RFQ that was drawn up ahead of the new procurement comprised 489 specific requirements or questions, most of which were of a functional nature. These were partly based on my previous professional experience (in translation, graphic design, printing, and technical documentation), partly on my, by now, 5 years' experience of our existing documentation system, and partly on refining what I considered would be mission-critical demands on the company in 5 years.
The functional demands were broken down into the following RFQ sections:
- Content management system (CMS)
- Transformations
- Special formatting constructs
- Notes
- Authoring environment
- DTD/Schema
- Translation management
- Indexing
- Page management
- Reviewing
- Terminology management
- Conditional formatting
- Compliance to 21 CFR Part 11
The following is a closer description of each section with a number of representative examples of questions and requirements from the RFQ.
Content management system
This section of the RFQ described a number of functional requirements and questions concerning the CMS system solution.
Examples from the RFQ:
74. Is the database storing the XML content a Native XML Database (NXD)?
92. Does the system provide search functions to carry out searches on a large batch of files in the CMS repository, using the following methods?
- Exact match search
- Phrase search
- Searches using regular expressions
- Searches using Boolean logic
- Proximity searches
Specify which search methods are supported.
95. Describe the metadata elements for components in the CMS system.
102. Does the system provide any means of automatically gathering all XML files in a specified publication and save this file collection to a location outside the CMS? If so, describe these methods.
106. When file conflicts appear when merging a branch into a main development line, can the user choose whether the branch files or the main development files shall take precedence when resolving the conflicts?
Transformations
This section was divided into output-independent transformations, transformations to PDF, transformations to HTML, transformations to HTMLHelp, and other transformations.
Examples from the RFQ:
120. Can the system be set up in such a manner that phrases with a specific attribute are still hyphenated even though a hyphenation algorithm does not find a proper hyphenation point?
176. In Adobe PDF, can cross references be evaluated against contextual criteria and the wording of the cross reference changed in a second-pass transformation?
179. Does the system support that a user specifies an external ICC profile for an Adobe PDF publication that will be embedded in the final Adobe PDF output?
193. Does the system provide functionality to process existing images to a color space (i.e., RGB) suitable for HTML output?
201. Can the system generate MIF (Maker Interchange Format)?
Special formatting constructs
The constructs in this section addressed a number of issues that have to do with the composition and technical aspects of the graphic production chain.
Examples from the RFQ:
207. Does the breaking of paragraphs into lines use a line-based line-breaking algorithm (as in most formatters) or a paragraph-based line-breaking algorithm (as, e.g., in TeX/LaTeX and Adobe InDesign)?
233. If a user specifies paper thickness, can the system, at a user's choice, output the cover as a separate file where the spine width is automatically calculated by the system, according to a given paper thickness and number of pages?
240. Does the system support that a user enters a specific attribute for an image and the system then gathers and outputs such images at one or more page-specific places in the publication?
246. Can the system automatically prevent short closing lines in a paragraph, if a user defines what constitutes a short line and what measures shall be taken?
Notes
This section covered the system's ability to manage different types of footnotes and margin notes. Most systems support an elementary composition of notes but, as within FLIR there are regularly a number of scientific publications that need to be managed in a professional manner, we wanted to set demands for a more advanced management of footnotes and margin notes.
Examples from the RFQ:
274. Does the system support independently numbered, multiple series of footnotes?
279. Can a user define the maximum ratio of a page that the footnote area is allowed to use?
280. Can a user control the footnote separator type, style, and spacing?
Authoring environment
This section in the RFQ covered the editing tool—its technical functions and capacity, interaction with the user, etc.
Examples from the RFQ:
286. Can text from, e.g., Microsoft Excel or Microsoft Word be pasted into the editor, retaining the correct character values?
288. Does the editor support change tracking (i.e., redlining)?
311. Does the authoring environment support any ASD-STE100 Simplified Technical English language and grammar checkers? If so, specify which STE checker is supported.
313. Does the editor support any scripting language that a user can use to carry out complex tasks? If so, specify the scripting language and provide an URL to a website presenting the language, or a whitepaper.
319. Provided that the system supports conditional formatting, can the conditions be visually displayed in the editor?
DTD/Schema
This section asked a number of questions concerning which DTD or which Schema was being offered, their degree of specialization, and any technical limitations.
Examples from the RFQ:
323. If the DTD or Schema that the system uses is a customized variant of a publicly available DTD or Schema, provide documentation on the differences.
324. Describe the DTD's/Schema's technical limitations with regard to supporting various types of document architectures. By this we refer to a DTD's/Schema's ability to not only support a traditional “book” paradigm (which typically includes cover, title page, TOC, main text, index, etc.), but to also support other types of paradigm, such as leaflets, brochures, letters, quick reference guides, full-screen presentations, etc.
Translation management
With increased demands in terms of global market penetration, when the RFQ was written, a great deal of focus was concentrated on a number of system requirements and dependence upon localization. These aspects were also referred to in this section of the RFQ.
Examples from the RFQ:
329. At time of importing of a translation project, can the Translation Management System (TMS) warn for private use Unicode codepoints, erroneously entered by a translator?
332. At time of importing a translation project, can the TMS warn if the XML structure (i.e., the XML tree) differs from the exported XML structure?
335. Can a user implement non-linguistic changes that were made in a source language into target languages without the need to send content to a translation agency?
341. At time of generation of a new translation project, does the TMS scan any phrase or paragraph in phrase libraries in the CMS in order to find already translated content?
Indexing
An index is an important tool for a reader to find relevant information in a publication, and a number of technical aspects around how an index would be supported in the workflow were covered in this section of the RFQ.
Examples from the RFQ:
344. Can the TMS gather index entries and output these entries in a more convenient form for the translator, and then, upon import of the translation project, reposition them to their correct places?
353. Does the system support multiple indexes, e.g., one index of personal names, one general index and one index with geographical locations?
362. Would the sorting of indices be compliant to Unicode Collation Algorithm/Default Unicode Collation Element Table (DUCET)?
363. If so, can the system enhance the sorting quality of Unicode Collation Algorithm/Default Unicode Collation Element Table (DUCET) with publicly available tailorings, needed to get the correct national sort order compared to the Unicode default sorting order?
Page management
This section covered a few aspects of loose-leaf publishing and change pages publishing—types of publication that are not unusual in the defense industry, to which several of FLIR's product segments are directed.
Reviewing
A well-functioning user interface and efficient workflow for the internal review of publications before the official release is central within the area of documentation, and this was emphasized in the RFQ.
Examples from the RFQ:
370. Can a user responsible for creating a review task set a due date when all reviews should be finished?
378. Does the system support real-time chatting to resolve disputes among reviewers?
380. Can a reviewer attach files to his or her comments, such as a screenshot or a Microsoft Word file?
Terminology management
This section covered a number of issues concerning whether the system had an integrated terminology-management function. One common technical solution is to manage this function via a plug-in (e.g., Acrolinx) in the editing tool. However, one of the suppliers had a fully integrated terminology-management tool.
Conditional formatting
Conditional formatting is a very powerful method for generating a large number of variants of manuals based on a small number of supermanuals, where items (e.g., product name, images, and sections) differ depending on a number of formatting conditions that were set up initially. As conditional formatting had been used extensively in the existing documentation system, this element was considered to be of interest in a future procurement.
Examples from the RFQ:
398. Can conditions be combined using Boolean logic?
400. Can a condition be combined with an xml:lang attribute?
Compliance with 21 CFR Part 11
The U.S. Food and Drug Administration's document 21 CFR Part 11 defines regulations on electronic archives and electronic signatures, and questions regarding system support for these were asked in this section.
403. Does the system technically comply to FDA 21 CFR Part 11?
404. If the system does not technically comply to FDA 21 CFR Part 11, specify if the system has technical limitations with regard to implementing the necessary features to meet or exceed the requirements stated in FDA 21 CFR Part 11.
Procurement
In May 2007, the RFQ was sent to six suppliers of XML-based documentation systems. Of these, five were European suppliers and one was in the USA. Five suppliers replied with a formal tender and a carefully completed requirement form/questionnaire, together with other documentation (project plans, development models, agreement proposals, etc.). One supplier chose not to take part in the procurement after receiving the RFQ, as the quotation officer felt it could not respond to such an extensive RFQ without invoicing FLIR for internal time.
All the tenders received underwent a thorough technical and business evaluation by me and other interested parties within FLIR during the autumn of 2007. I had not expected any suppliers to be able to offer a system that complied fully with the technical requirements laid out in the RFQ. There was a large spread among them with regard to how well they met the set requirements and in which fields they were technically stronger or weaker.
In order to present the evaluation to personnel higher up in FLIR, an executive summary was drawn up in which the technical analysis of the tendered systems was summarized in the following seven main areas:
- Authoring environment
- Content management system
- Formatting engine and maintenance of style sheets
- Translation management
- Terminology management
- Review workflow
- International collaboration
In the executive summary, I recommended that the Swedish management go ahead with one of the suppliers to a proof-of-concept phase. At this stage, the procurement was delayed by over one year due to internal workload and intense product-introduction phases within FLIR. During this time, the selected supplier was acquired by another company, and the supplier finally acknowledged that it would not be able to complete the implementation in the foreseeable future. Therefore, I decided to go ahead with the supplier that had been rated as number two in the technical evaluation—the company Simonsoft.
Simonsoft (http://www.simonsoft.se), based in Gothenburg, has 10 employees and is a wholly owned subsidiary of the PDS Vision Group (http://www.pdsvision.com)—a supplier of IT products and services in the PLM field, principally from the American company PTC (http://www.ptc.com). The company was founded by a number of people from PTC who, in connection with the acquisition of Arbortext in 2005, broke away from PTC. Since then, Simonsoft has been the sole distributor of these products in the Northern Europe market. Today, the company is also represented in England and Germany, with retailers in Canada. Simonsoft also offers varying degrees of integrated solutions based on products from PTC, and this was a solution included in the tender they offered FLIR in 2007.
Description of the System Solution from Simonsoft
The system from Simonsoft is based on a number of well-known, tried-and-tested modules and software that are integrated and packaged into a comprehensive solution to create and maintain technical information throughout its life cycle.
The system is based on the following modules and software:
- The editing tool Arbortext Editor from PTC (see Figure 1). This editing tool for SGML and XML was introduced in 1991 under the name Adept Editor by Arbortext in Ann Arbor, Michigan, USA, and is one of the most widely used editing tools. Arbortext was acquired by PTC in 2005.
- The Simonsoft CMS version-management system, based on Subversion from Apache Software Foundation. Subversion, an open-source program for version management, was released in 2000 and has several hundred thousand installations the world over. Simonsoft CMS also contains a Web interface for Subversion and has been designed to cater to a fully Web-based management and overview of all files in the version-management system.
- The Advanced Print Publisher formatting engine from PTC. This formatting engine, one of the most advanced engines on the market, was previously known as Advent 3B2 and was developed originally by Advent Publishing Systems in England. The company was acquired by Arbortext in 2004.
- Arbortext Styler from PTC. Arbortext Styler is an advanced tool for developing and maintaining style sheets for Formatting Output Specification Instance (FOSI), Extensible Stylesheet Language Transformations (XSLT), and the proprietary style-sheet language for the Advanced Print Publisher formatting engine.
Simonsoft's solution is fully cloud-based and can be accessed over an https:// connection from any geographic location and computer, provided the computer has the necessary security certificates installed.
From a user perspective, it is, above all, the Arbortext Editor tool and Simonsoft CMS that the user is in contact with and I therefore limit my description to these.
The Arbortext Editor tool
As mentioned previously, Arbortext Editor is one of the most widely used editing tools for SGML and XML and has a long history. It has a user interface that visually resembles a word processor, which is an advantage when training new authors, as most of them have experience with a Microsoft Word workflow. This editing tool can be easily integrated with external databases and has robust support when it comes to the importing of engineering data from, e.g., Microsoft Excel or Word. A detailed description of the editing tool is beyond the scope of this article, and I therefore refer interested readers to the documentation available on the PTC website (http://www.ptc.com).
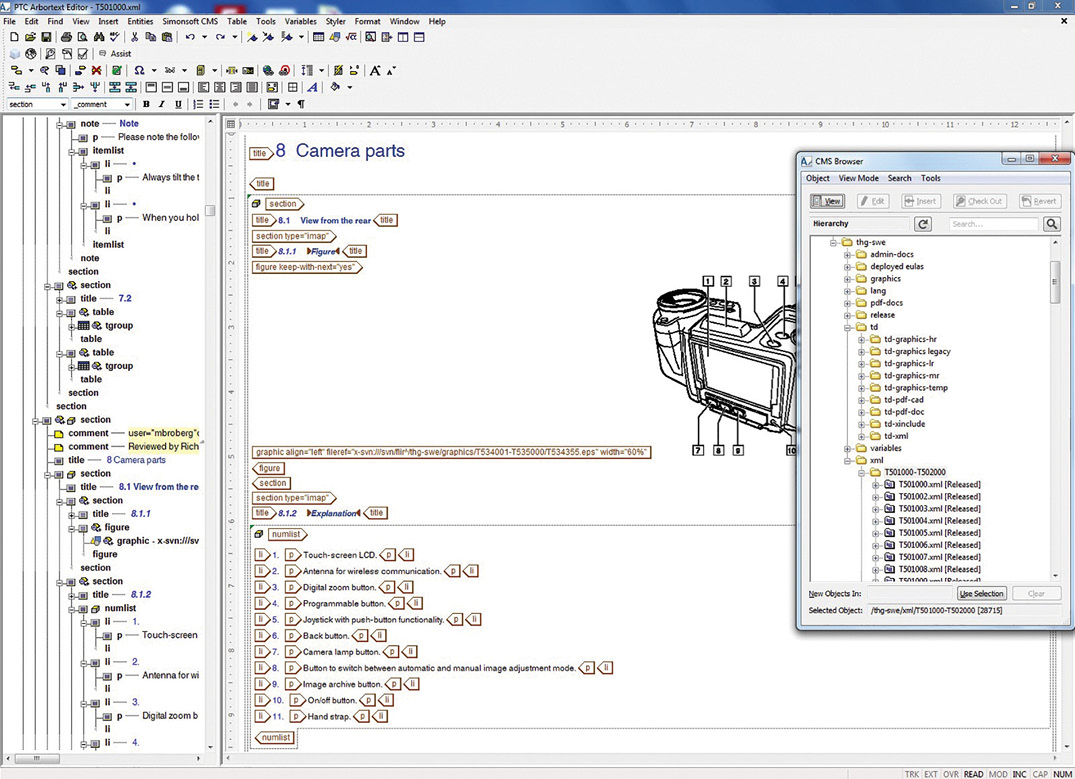
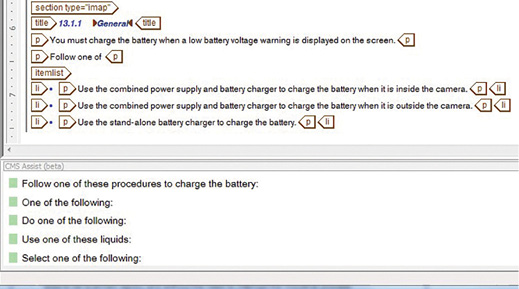
Instead, I would like to look in detail at CMS Assist—an adaptation of Arbortext Editor, developed by Simonsoft, which forms part of the system solution. It offers excellent support to authors in terms of linguistic consistency and also greatly minimizes translation costs.
The CMS Assist tool is fully integrated in Arbortext Editor. When an author makes a brief pause in writing, the tool makes a rapid look-up in the database for linguistically similar segments in previously released documents and possible existing translations. These segments are displayed in a split-screen view at the bottom of Arbortext Editor. When the author sees a suitable segment to reuse, he or she can click on it to see whether it has been translated previously.
If the author decides to use the segment, he or she can double-click on the segment in order to reuse it in the current context. The segment will then be inserted into the text and set with a unique checksum attribute.
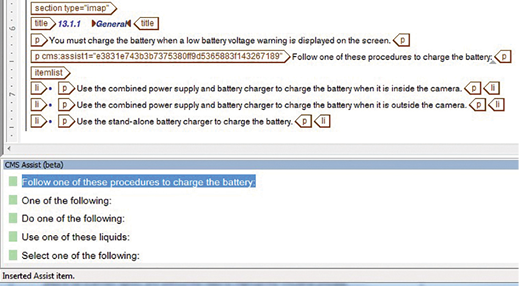
This approach has three compelling advantages:
- It helps the author establish linguistic and terminological stringency in his or her writing, which has a positive effect on the customer's experience and understanding of the text.
- It provides system support for the author in order to avoid a plethora of linguistic variants of significantly identical expressions and segments and thereby minimizes so-called “fuzzy matches” in the translation stage, which always lead to additional expense, depending on the segment's percentage of hits in the translation memory.
- The author can see directly if one or another segment suitable to the context has already been translated and is thereby given the opportunity to select a segment that has already been translated, thus avoiding additional translation costs.
Similar solutions are already available for Arbortext Editor in the form of plug-ins from other suppliers but at a completely different cost and with more complex system and version dependencies. These solutions often require that separate servers holding sentence databases are being commissioned and maintained. Some suppliers certainly offer additional functions in their tools, e.g., grammar checks, linguistic style, and stricter terminology management, but, in my experience, grammar checks and linguistic style are relatively easy to control procedurally in an existing documentation process. My analysis of how CMS Assist works and how it can provide support for authors in their daily work indicates that this is a very cost-efficient solution compared to other offers on the market.
Simonsoft CMS
As mentioned above, Simonsoft CMS contains a Web interface for Subversion. This Web interface allows excellent control of all objects, configurations, and dependencies in the version-management system and also offers the user a large number of tools for managing and configuring files.
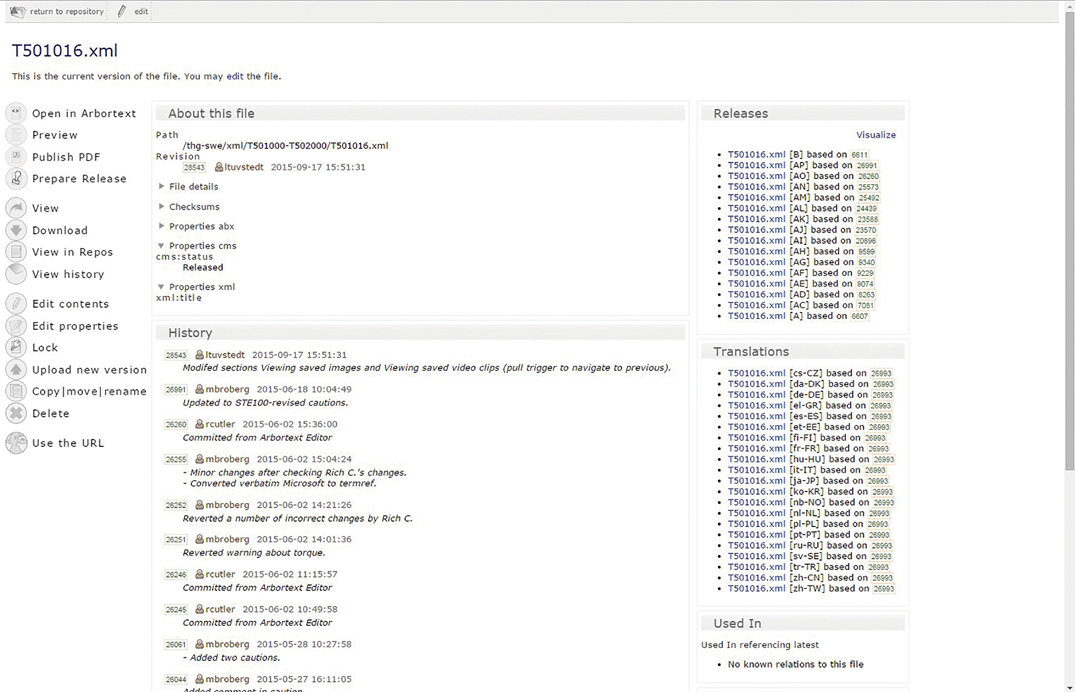
The following operations can be performed in Simonsoft CMS:
- Open and edit XML files in Arbortext Editor.
- Preview and publish XML files.
- Release XML files.
- Create translation projects and pretranslate an XML file using the system's internal translation memory before handing over to a translation agency.
- Show XML files in code view.
- Download or upload new file versions.
- Edit file properties.
- Copy, move, or rename files.
- Delete a file.
- View the version history for each file and open any historic version.
- See what releases there have been of an XML file.
- See what translations have been made based on a certain XML file.
- See in what other XML files a given file is used (where used).
- See what other files are included in a given XML file (dependencies).
- Visualize relationships between XML files, their releases, and translations.
As mentioned above, Simonsoft CMS offers the ability to automatically pretranslate XML files from previously existing translations and this is one of the most powerful functions in the system. The function builds on the assumption that the linguistic risk of automatically translating block elements from the <section> element down to and including <p> and <row> elements is sufficiently low to make such a pretranslation advantageous from a business perspective. From a technical viewpoint, 100% matches of the contents against the translation memory are moved from the translation provider to the documentation system, which has several advantages:
- Authors are given full control over which translations are used, which, depending on what the technical flow looks like at the translation providers, is not always the case when this matching is done by them.
- Corrections of existing translations can be done easily in the system and the latest corrected instance of the paragraph or section is used automatically during subsequent pretranslations.
- Some translation providers charge for 100% matches—this charge will disappear completely with this function.
The lower limit in the standard system settings for pretranslation is set to <p> and <row> elements, but this can be reconfigured if a break point at other elements is considered to be better. From a linguistic perspective, there is a minimal but actual risk that a pretranslated block element is not suitable contextually in relation to the previous or next non-pretranslated block element. For this reason, all pretranslated translation projects are generated as complete but bilingual XML documents, where the translator is able to see the pretranslated text as well as the text for translation. Attributes are set in different ways for these and the blocks are therefore easy to manage at the translation stage.
Within FLIR, the pretranslation function has been a great success, and most projects sent to translation providers today are already pretranslated by up to 80–90%.
Migration Projects
As mentioned earlier, the success of XML within the thermographic division has led to other divisions and business units becoming interested in migrating their documentation to this new workflow. The migration project therefore also included two further units in addition to some recent and planned migrations. The project can be divided into the following four phases:
- Migration of the Infrared Training Center's (ITC's) documentation
- Migration of Governmental Systems Sweden's documentation
- Migration of the Instrument division's existing XML documentation
- Recent and planned migration projects
Migration of ITC's documentation
The ITC is a global infrared training organization specializing in the certification of thermographers according to international standards. It is a business unit of the FLIR Systems' Sales organization, with the primary objective to grow the market through knowledge.
At the time of migration, ITC had approximately 250 archived documents, with approximately 50% considered “living.” Each archived object existed in a number of languages in up to 25 versions. The documents were primarily Microsoft Word and PowerPoint files. ITC documents were created by a core team of 3–6 people in different locations and countries. The documents were reviewed by approximately 10 people located in Sweden and Boston, then tested globally during a beta period, and finally released for use by FLIR staff and licensed partners, numbering 30+ entities.
It soon became clear that the use of PowerPoint was firmly anchored within the ITC organization. The lecturers and authors who drew up training materials for courses were also very well versed in the use of PowerPoint and all of its functions. Our analysis, done together with Simonsoft, was that the only way to globally anchor a new workflow was to offer a similar type of publication to PowerPoint—but with the whole force of the XML-based infrastructure under the surface. However, from a technical perspective, the goal could, naturally, never be to offer the much greater number of features that PowerPoint has. The need for the authors to adapt to a new workflow and a significantly smaller range of features could not be circumvented. However, from a business perspective, we saw that this could be anchored, given the undoubted benefits that an XML-based workflow has and the framework decisions that were taken high up in ITC's global organization.
In order to satisfy the need for a slide-based publication concept, it was necessary for Simonsoft to make certain adaptations to its DTD, as, at the time of the migration, this did not contain a slide element. Simonsoft's DTD—called techdoc.dtd—is a simplistic DTD for covering most of the needs of technical documentation and has only 32 block elements, four reference elements, and 11 inline elements. As with most of the other DTDs for technical documentation, it is based on the assumption that information is to be allowed to flow freely over to the next page if there is not enough room on one page. However, a slide-based publication concept is page-centric and based on the opposite assumption—that all significant information around a point in the lecturer's presentation fits onto one page.
PowerPoint also has a view called notes pages. These hold notes that the lecturer has made in order to assist him or her during the lecture (e.g., support words, author's comments, or questions for the students). These notes are not visible during the presentation and can only be seen by the lecturer in a split-screen view on his or her computer. A similar function was considered to be an important component for ITC.
For these reasons, Simonsoft added two elements in order to handle ITC's course material—<slide> and <notes>—and developed two different style sheets that complied with ITC's brand identity:
- Standard—a traditional A4 publication in portrait format used for more extensive course material for certified customers.
- Slides—a page-centric presentation similar to PowerPoint with the possibility, through profiling, of formatting notes pages on separate pages.
ITC's organization was affected by restructuring measures during the spring of 2010, which led to the loss of important stakeholders as well as the organization-wide drive to achieve the documentation migration. This is an absolute condition if such a project is to be implemented successfully. As a consequence, the migration was reduced such that only the course material of the Swedish ITC site was covered. Despite the significantly smaller scope, ITC's technical author in Sweden has experienced a significant increase in efficiency compared with the management of the corresponding documentation in the old PowerPoint flow—not least in the traceability, modularization of documentation, and the translation process. The author has also been a driving force in the efforts to embrace new standards and has, together with an external supplier and others, developed online courses according to Sharable Content Object Reference Model (SCORM), based on the course material that is maintained in the documentation system. SCORM is a collection of technical standards for Web-based e-learning, originally initiated by the U.S. Department of Defense.

Migration of Governmental Systems Sweden's documentation
Governmental Systems Sweden (here called GSS) is a business unit of FLIR Systems, which develops and manufactures land-based systems and sensors for government agencies and military customers. Their principal product segments are the following:
- Fixed surveillance systems for border protection, coastal surveillance, vessel traffic monitoring, and airport security.
- Vehicle vision systems, i.e., technologies for situational awareness and driver's vision enhancement.
- Thermal weapon sights for anti-armor and anti-aircraft missile systems.
The existing workflow for GSS documentation involved a technical author writing manuals in Microsoft Word. Once these manuals had undergone internal review and approval, the Word files were sent to an external company that imported the text into Adobe InDesign, applied the correct character and paragraph formats, and created high-resolution PDFs that were returned to GSS for archiving, distribution, and forwarding to external printing plants. This workflow was not only inefficient in time but was also costly. Responsible persons within GSS were, therefore, highly motivated when it came to a new and more efficient workflow.
An initial migration took place during 2011 and included around 40 chapters and 250 images, which represented only a small fraction of the GSS documentation. The GSS technical author thereafter carried on working with further migration of existing documentation and built and configured publications in the system.
Today, the GSS technical author maintains around 70 technical publications in the system and has experienced, as was the case with the ITC author, greatly increased productivity and cost efficiency compared with managing the documentation in the previous workflow. In this context, it must be said that GSS does not, as a rule, translate any documentation and does not therefore benefit from the system's streamlining of the translation process.
Migration of the Instrument division's existing XML documentation
The most complex migration in the project was undoubtedly the migration of the XML-based documentation from the existing legacy system to the new system solution from Simonsoft. Our awareness of this complexity meant that we deliberately chose to undertake this process last in the project—two years after the ITC migration and one year after the GSS migration. A further aspect that hindered the migration was the fact that the legacy system was a live production environment until all the XML files and images had been imported into the Simonsoft solution—after which the new system had to function immediately in a production-verified state with an uptime of virtually 100%. It was not possible to maintain the technical publications in parallel in the two systems, and, in the very intense introduction phase in which the migration was to take place, there was no chance of pausing the documentation work in the legacy system and restarting it some weeks later in the new system solution.
The migration project included a number of known and necessary technical steps but also a number of steps that depended on different business and technical aspects that FLIR was obligated to decide upon.
The known and necessary steps were the following:
- Refactoring of existing XML files from the legacy system's DTD flex.dtd to Simonsoft's DTD techdoc.dtd. We did not expect any directly technical problems because flex.dtd, just like techdoc.dtd, is a simple DTD with about the same number of elements.
- Replacement of internal, external, absolute, and relative paths to XML and image files.
- Importing of XML and image files to the new CMS.
- So-called “bursting” of XML files, which, in this context, involves automated opening of files in Arbortext Editor for the correct setting of various file attributes.
- Development of eleven different style sheets for PDF and two for HTML.
In addition to these steps, there were also a number of investigative issues related to various business and technical aspects:
Conversion range At the time of migration, there were around 700 manuals, including translations, being maintained in the legacy system. These 700 manuals were generated from a number of configuration files that defined, e.g., conditional formatting, language, product name, and publication number. There were just over 9,700 XML files and 6,300 image files in the system. Ahead of the migration, the migration range was the subject of extensive discussions between Simonsoft and myself. These discussions concerned, among other things, whether we should convert both source and target files, and whether, for traceability reasons, we should also include historic revisions of all files. A complicating factor was, as mentioned earlier, that the time between the closure of the legacy system and the start of the new production-ready publication architecture—with all files converted and an uptime of virtually 100%—must be kept to a minimum. In the end, we chose to convert only the XML source files (i.e., English) and planned a replication of target files by using the exported translation memories. The image files were migrated in their entirety. A complete database and file export from the legacy system for archiving purposes was also done in order to maintain full historic traceability.
Relocation of certain #CDATA Parts of the technical information that had been maintained in the legacy system were entered into tables. The incentive to first enter this information into tables was that a number of publications were maintained according the Information Mapping methodology and, for technical reasons in the formatting toolchain at that time, a tabular markup was needed in the XML file in order to visually render a structure in accordance with Information Mapping. A formatting solution that created this tabular rendering in the publishing workflow without the need for a tabular markup in the source files would have been preferable, but there were various technical obstacles to this procedure. The table element is also—from a theoretical XML perspective—a problematic and not especially “orthodox” element, as it not only represents content but also a visual concept. Consequently, this is an element that should be avoided as much as possible and be used only when there is no other possible element that can be used to solve the same task. At the time of the migration, therefore, I wanted to resolve these tables and convert them to a linear flow of text in the form of sections. However, I wanted to keep the theoretical possibility of replicating the historical rendering in a future formatting scenario, and we therefore set attributes on all converted tables in order to have full backward traceability.
Renaming of XML and image files At the time of migration, I wanted to synchronize the naming conventions for XML and image files with the technical business regulations in force for other kinds of item data of the Swedish organization (e.g., construction articles, composite articles, purchase articles, and BOMs). The existing naming in the legacy system was based on two numerical series—one for XML files, 2xxxxxyy, and one for image files, 1xxxxxyy, where xxxxx was a five-digit number incremented by +1 for each new file, and yy was a signal code for the file language (e.g., 03 for English). The new naming convention involves the prefix T (for thermography) followed by a serially incremented six-digit code (e.g., T501016 for an XML document). In this context, I chose to abandon my earlier methodology that included a two-digit suffix for language. Instead, in the new system, this is handled using metadata, which is technically a more elegant solution.
Quality assurance of certain texts In the legacy system there were a number of publications containing text on which I wished to carry out further linguistic and technical quality assurance—but not changes in meaning—and the technical consequences of this became the subject of extensive discussions in which we engaged language technologists from our translation providers, conversion specialists from Simonsoft, and the accredited linguists we use for reviewing our publications. As mentioned above, by then we had made the decision to convert only the English source file and replicate all translations by exporting the internal translation memory of the legacy system. The problems encountered were more extensive than I can go into in this article but partly concerned the fact that even minimal language changes to texts during migration would create a very large proportion of so-called “fuzzy matches” if these converted publications were then matched against the legacy system's exported translation memory at our translation provider. A quick calculation showed that the large number of fuzzy matches would be unacceptable from a business-economic perspective. One possible solution to this problem, which was the subject of a large amount of discussion, was to make the planned quality audit of the source files outside the legacy system and then structurally align the XML files with the existing translations and generate a new paragraph-based translation memory based on this alignment. In the end, however, we decided not to carry out the quality audit in question during this phase—a decision that, in hindsight, I think was good, as technically the possibility of carrying out such a project within the new system without establishing fuzzy matches is much greater.
After all the points of the investigation had been investigated and the relevant decisions had been taken, the Simonsoft team began the migration of the existing documentation. This was done iteratively through the migration of frozen subsets. The relocation of #CDATA and the change of the naming convention, as mentioned above, became technically complex steps in this project. However, despite this, it was possible to undertake the migration in a controlled manner and in line with the established time schedules.
In accordance with the manual for graphic brand identity that was previously established at FLIR, Simonsoft developed nine different style sheets for PDF and two for HTML in parallel with the migration:
- A4, 1 column
- A4, 2 column
- US Letter, 1 column
- US Letter, 2 column
- A5, 1 column
- A6, 1 column
- 118 mm × 165 mm, 1 column (4.65 in. × 6.50 in., a sheet-optimized size for printed matter)
- Technote A4 (1 column with sidebar, for technical memoranda)
- Technote US Letter (1 column with sidebar, for technical memoranda)
- A chunked HTML-based help format, with Java functionality
- A non-chunked HTML-based help format, without Java functionality
Subsequently, two additional style sheets were added to handle FLIR's 5000-page product catalogues in A4 and U.S. Letter format.
Recent and planned migration projects
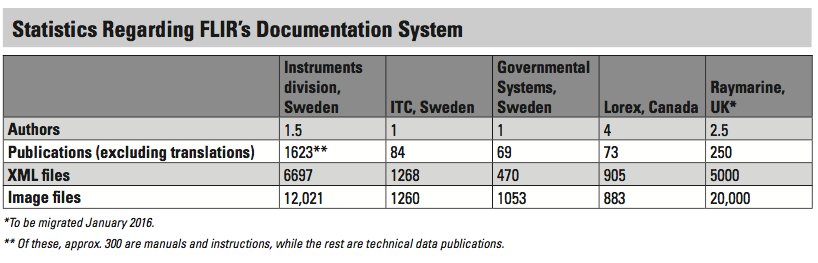
In December 2013, we migrated some of the documentation at the FLIR-owned company Lorex (https://www.lorextechnology.com), a Canadian manufacturer of camera systems and solutions for security surveillance in homes, businesses, and industry. Lorex has four full-time authors who maintain documentation in the system and, after about one year of using the new system, the team leader for documentation work was able to identify great savings in the translation stage. The Lorex team has also come up with several suggestions for improvements to style sheets and systems, and, on their initiative, the ability to output internal review comments in the PDF has been introduced.
Raymarine—a world-leading manufacturer of marine electronics—was acquired by FLIR in 2010. The documentation department of Raymarine has been working with XML for seven years, and all technical documentation is written in Darwin Information Typing Architecture (DITA—an XML data model for modular authoring). Their existing system—like the case at FLIR—is based on products from PTC but with PTC's CMS Windchill instead of Simonsoft CMS. Together with Simonsoft and FLIR, the head of documentation at Raymarine has identified a number of positive effects of a migration to the new system, and migration is therefore planned for January 2016. The anticipated positive effects include the following:
- License cost sharing
- Improved release and translation workflow, providing significant time and cost savings
- Moving away from a customized CMS build to an “off-the-shelf” configuration, which will reduce the cost and complexity of future upgrades
- Cost-effective route to non-PDF output formats such as HTML5
- Potential for future repository sharing with the wider FLIR organization
Cost Savings
An analysis over a 10-year period confirms my estimation reported in my previous article (Broberg, 2004): a saving of around 75–80% of the cost of handling the corresponding documentation in a traditional workflow based on software such as Microsoft Word, Adobe FrameMaker, Adobe InDesign, and the like. For the translation workflow, a conservative estimate indicates a saving of approximately 25–30%.
The sites that were migrated between 2010 and 2013—ITC, GSS, and Lorex—have all been able to identify the same types of saving. These concern the following:
- A sharp increase in authors' productivity
- Complete elimination of desktop publishing work—which was either done by the authors themselves, by an external supplier, or, in the case of translations, the translation provider
- Dramatically reduced translation costs
In addition, there are many other reasons the new system has led to savings. The value of these is difficult to calculate, but they are undoubtedly relevant in this context and are dependent on processes, the IT infrastructure, and the very efficient workflows that can be built up around XML:
- Modular writing and reuse of content
- Automated publishing to multiple output formats
- Full version control and traceability of all objects
- Simple impact analysis of planned changes (where used and dependencies)
There are also a number of technical benefits of XML that ought to be identified as highly mission critical in an analysis of a modern, corporate, long-term information strategy:
- A standard that is approved for long-term storage
- A non-proprietary data format
- A human-readable, non-binary data format
Lessons Learned
Based on my experience of system procurement, my experience working in an XML-based workflow, and the system migrations I have been responsible for, there are a number of lessons that can be drawn. These concern, among other things, the following:
The establishment of XML as a best practice for documentation benefits from a top-down approach This is perhaps my clearest conclusion. The spread of XML for technical documentation has been slower than I would have predicted, and there are still a number of departments within FLIR that work with traditional documentation processes. I believe that the main reason for this slow dissemination might be that the establishment of an XML-based workflow should be linked to a global information strategy, the focus of which is technical documentation as an added value in its broadest sense. Such a strategy can probably be enforced more successfully at a corporate level.
Previous training or experience of the writers lacked predictive value This is one of the more interesting conclusions. During the migrations, I assumed that people with many years of experience of, e.g., Adobe FrameMaker, which imposes a structured method of working with documentation, would find it easier to get used to an XML-based workflow. However, this did not happen and the opposite was not uncommon. There are examples of authors who were only familiar with Microsoft Word and had never worked with XML but who very soon became well skilled in and motivated to use the new work method.
PowerPoint as best practice and how strongly it was anchored within ITC were underestimated In retrospect, the introduction to ITC of a page-centric type of publication in PDF based on Simonsoft's DTD was not particularly suitable. I underestimated how deeply rooted the use of PowerPoint was within the global ITC organization—both as an information tool and as an information carrier—and I am doubtful that it would have been possible to gain acceptance of the proposed type of publication. An in-depth analysis of ITC's documentation culture should have been carried out in order to find suitable processes and methods. One way forward could have been to generate PowerPoint files with a basic set of version-managed texts and images and then allow lecturers and authors to carry on working with PowerPoint tools in order to lay one last creative hand on the presentations. The possibility of such a process should have been studied more closely.
A more appropriate choice of DTD As mentioned earlier, the Simonsoft DTD—techdoc.dtd—is a simplistic DTD with a minimal number of elements to manage the majority of information types and demands that exist within technical information. In this way, it is similar to the DTD that was used in the legacy system (flex.dtd). Without a doubt, there is much to be said for such a DTD—a small number of elements for the author to learn, low support and maintenance costs, etc. However, as the global system owner, I must look at the choice of DTD from the perspective of information security and the associated business risks, as Simonsoft's DTD is proprietary insomuch as it is not used by any people other than Simonsoft's clients. The risk must be assessed in terms of a worst-case scenario. What would our ability be to independently replicate the global documentation environment to a minimum functional level in, e.g., 24 hours if critical core abilities or business structures were lost in the system supply chain? In light of this, today I would choose DocBook. This is also a DTD that Simonsoft offers in its system and of which I have a lot of experience in other documentation projects including technical data and multilingual publications. The advantage of DocBook is that it is maintained by the Organization for the Advancement of Structured Information Standards (OASIS), that it is a widely used DTD, that it is exceptionally well documented (http://docbook.org), and that there are several inexpensive editing tools that, without any configuration, can be used directly for publishing to PDF, HTML, WebHelp, RTF, etc. Against this it can be argued that an XSLT script could be produced for use in a disaster recovery to convert all of FLIR's documentation from Simonsoft's DTD to the DocBook DTD. While this is technically feasible, the cost of establishing such a script would easily escalate and would involve further steps to be handled in a critical situation. It would also break the version management of all objects in the CMS. It can be argued that DocBook has a very large number of elements compared with a simplistic DTD like techdoc.dtd and that some authors therefore feel that the documentation process is more sluggish. This view is also correct but Arbortext Editor can be configured so that most of these elements are not visible to the author and the experience would be more like writing in techdoc.dtd. On the other hand, a DTD such as DocBook does not have the flexibility that a proprietary DTD can offer, where new attributes can easily be added to handle customer requirements (which occurred repeatedly during our project). Currently, a discussion is taking place between Simonsoft and FLIR regarding business risks and how to keep them at an acceptable level in the future.
After several years of live operation of the new documentation management system, it is our assessment that we have gained a very powerful solution, which means we are well equipped for the future. In addition, the solution has such a dynamic architecture that it can easily and cost-effectively be modified and further developed for the various types of versioning, formatting, and publishing needs that may arise in the future.
Reference
Broberg, M. (2004). A Successful Documentation Management System Using XML. Technical Communication, 51(4), 537–546.
About the Author
Mats S. E. Broberg is Technical Documentation Manager at FLIR Systems, a global leader in civil and military infrared cameras and image-analysis software. He has worked at FLIR Systems since 1999 and has been responsible for two procurements of XML-based documentation management systems. His previous work experience includes a position as a technical writer at a medical technology company and as an independent consultant in graphic design, commercial printing, and publishing. Contact information: mabr@flir.se or http://se.linkedin.com/in/matsbroberg.
Manuscript received 24 September 2015, revised 23 November 2015; accepted 23 November 2015.
