By Nupoor Ranade and Alexandra Catá
ABSTRACT
Purpose: To evaluate the usability of chatbot design and how chatbots and search compare for information delivery and usability, we ran two test cases. In the first, we focused only on chatbot usability, information delivery, and design. In the second, we compared chatbot responses to those provided by search engines to identify areas of similarities and differences in terms of accuracy, functionality, and usability.
Method: Test Case 1 uses an exploratory method to analyze chatbot functionality. Test Case 2 uses content analysis of search responses and corresponding chatbot responses. Data from two major telecommunication companies' websites—Sprint and Verizon—was used for both.
Results: In Test Case 1, we found that chatbots are generally more flexible and helpful when they provide information directly in the chat pane and allow free-form text entry, in addition to several other related characteristics. This was critical to receiving the information we needed efficiently and accurately. Results of Test Case 2 show that chatbots provide less information than search results, have longer wait times, and rely less on algorithms to get responses and more on constant updating.
Conclusion: Based on Test Case 1, we developed a heuristic that addresses usability, information design, and accessibility. In Test Case 2, we determined that search functionality is better than that of chatbots in terms of 1) speed of response, 2) accuracy of responses, 3) multiple formats for content delivery, and 4) ease of use
and accessibility.
Keywords: chatbots, search, heuristic, information design, usability
Practitioner’s Takeaway:
- Content can be reused and integrated into chatbot information design.
- By comparing user behavior for using search in comparison to chatbots, technical communicators can make informed choices about which tools to use for product documentation websites.
- Chatbots feel more helpful when there is flexible user input, the chatbot is transparent about being a non-human entity, the chatbot is aware of its limitations, information is accurately given either in the chat pane or through a link, and the chatbot is responsive during conversation.
- Heuristics provided here can be used to design, develop, and test chatbots at a conceptual level.
“I believe that at the end of the century the use of words and general educated opinion will have altered so much that one will be able to speak of machines thinking without expecting to be contradicted.”
— Alan Turing (1947)
INTRODUCTION
Chatbots, also known as conversational agents, are on the rise and one of the most popular forms of artificial intelligence (AI). A chatbot is “a computer program designed to simulate conversation with human users, especially over the Internet” (Oxford Dictionaries, n.d.). Although chatbot technologies for developing interfaces have existed since the 1960s, the addition of intelligence through machine learning (Radziwill & Benton, 2017) and easy-to-use tools such as ChatFuel and Botsify have made chatbots easier to implement and train. They can now be easily integrated into existing information systems and social networking sites, such as Facebook, and developer productivity tools, such as Slack and GitHub. This has resulted in an exponential increase in the use of chatbots for online interactions since 2005.
Chatbots are participating in more than one-third of all online interactions known to take place between 2005 and 2015 (Radziwill & Benton, 2017). Chatbots help corporations by “reducing the time-to-response, providing enhanced customer service, increasing the rate of satisfaction, and increasing engagement” for customers (Radziwill & Benton, 2017). They carry out most of these activities by solving users’ problems, either by giving users more information or navigating them to the place where they can find more information. It is in these areas that technical communicators play important roles.
Hughes (2002) argues that technical communicators restructure technical information in a user-centered manner and relate it to specific applications. They also create new knowledge that is presented in actionable terms, and the knowledge they generate helps to mitigate costs for corporations by reducing investments on support and development (Redish, 1995). Because chatbots are intended to serve as support tools, it is important to compare how information provided by chatbots differs from other content published in technical communication work, especially product documentation websites. Search engines also play a key role in disseminating information. Technical communicators are often tasked with converting information in a form that is easily traceable by search engines (Killoran, 2010). Although there is some research on designing content suitable for search (Killoran, 2009; Killoran, 2010; Killoran 2013; Laursen, Mousten, Jensen & Kampf, 2014), similar literature on chatbots is almost nonexistent. Addressing this gap is important as it will help technical communicators understand how to design and format content for chatbots or other conversational agents such as Siri and Alexa, which are also popular. Considering the similarities to other tools for which technical communicators have designed content before, how can we decide which tool is more valuable for organizations? To do this, we must measure the effectiveness of each of these information tools. This research examines chatbots through two studies.
Test Case 1 examines support chatbots and their responsiveness to a set of inquiries where we evaluate the usability, information design, and content delivery of the chatbot. Test Case 2 compares chatbots with the website’s search function to understand which is better. Differences between these tools help to highlight the characteristics of chatbots and search. These findings—advantages of one tool over another—when incorporated into the design and development of information tools, can make the tools more effective and impactful.
Chatbot design depends on a number of factors. Although rhetorical factors like purpose, audience, and context play an important role, the effectiveness of chatbots can be said to be on par with the product documentation site only if they provide equal access to information or make information finding easier. Further, by expanding the comparison from the search feature and including two chatbots in the study, we were able to derive characteristics that could be used for evaluating chatbots, making them more effective means of communication.
In this study, we conducted exploratory testing with two telecommunications chatbots to understand the basic design principles necessary to create an effective support chatbot. We included AT&T’s chatbot in our initial investigation but removed it from the study because it required users to log in.
The results reported in this article enhance our understanding of chatbots and also help technical communication practitioners and researchers to:
- better understand whether chatbots can enhance the way we deliver content to audiences;
- use a design heuristic to develop, test, and research chatbots that provide troubleshooting and technical support;
- collaborate with other fields where such research is being conducted; and
- better understand perspectives, assumptions, and industry expectations about the value that chatbots bring and how to incorporate it into technical communication, information design, and publication management classrooms.
In the following sections, we first map out the key components in designing a chatbot and search feature for an information website. Then, we provide detailed comparisons between chatbots and search, specifically based on the design requirements, user experience, and content delivery models. Further, we discuss criteria that can be used to evaluate the quality of chatbots. Finally, the article highlights the impact of chatbot technologies on technical communication and ways to study chatbots for a better understanding of their value as well as for making cases for their adoption.
BACKGROUND ON INFORMATION TOOLS
Some of the techniques to provide appropriately structured content for both chatbots and search involve writing and designing web pages in ways that are both broadly strategic and also meticulously tactical to ensure that they are read optimally by humans as well as search engines and chatbot algorithms. Such a combination of writing, reading, web page design, and analyzing audience needs marks these as precisely the kind of communication techniques that deserve to be the object of technical communication research.
Although chatbots and search are not new, advances in technology have made them effective solutions for providing customer support. Tools like chatbots and search were developed to address this need for customer support services and generate responses to customers’ queries without human involvement (Paul, Latif, Adnan & Rahman, 2018). While search is designed to crawl through the entire data and retrieve results for specific keywords, chatbots are developed to “handle natural language conversation with the user and serve them with the desired service” (Paul et al, 2018). The algorithms for both these tools are designed based on the complexity involved in simulating human information-seeking behavior (Tredinnick, 2017). Instead of attempting to simulate general human intelligence, algorithm developers and designers of chatbots have moved to a data-based approach. These algorithms use data from previous users’ queries to produce better responses.
Impact of Algorithms on Technical Communication Work
Algorithms are programs designed to be functionally automatic, and they act when triggered without any regular human intervention (Gillespie, 2014). For example, the Google search algorithm crawls the public web to index, pull, and display all of the relevant data when a user makes a request. The data consumed by algorithms can be structured or unstructured. Structured data is composed of clearly defined data types whose pattern makes them easy to search and categorize, whereas unstructured data does not have clearly defined types and patterns that cannot be easily searched, such as audio, video, and social media postings (Taylor, 2018).
While search algorithms function on existing data, chatbot (especially machine learning based) algorithms work on mining unstructured data drawn from the real world and often natural language sources (Tredinnick, 2017). Technical communicators are tasked with structuring unstructured data that can be consumed by these algorithms to produce accurate responses to users’ questions. To do so, they need to consider different dimensions of data to make it easy for algorithms to process it—“how data was defined, collected, transformed, vetted, and edited (either automatically or by human hands)” (Diakopoulos, 2016). While these processes are not fully automated in technical communication work, they influence and impact algorithms and their success in either processing natural language or working from a particular dataset. In short, while strategizing content delivery or creating information frameworks, technical communicators prepare data so that it is easily findable by users (for example, through website navigation) as well as algorithms (for example, search engines).
Understanding search algorithms are important for technical communicators because search is the predominant method for information delivery. Search algorithms used to be based on simply tallying how often the actual search terms appear in the indexed web pages, but search algorithms now enlist natural language processing (NLP) techniques to better “understand” both the query and the resources that the algorithm might return in response (Gillespie, 2014). Additionally, search engines like Google regularly engage in usability testing, especially “A/B” testing, presenting different rankings to different subsets of users to gain on-the-fly data on speed and customer satisfaction, which is then incorporated in a subsequent upgrade (Gillespie, 2014). Functionally, search provides additional advantages. Among the communication methods that would attract people to technical communication business websites, Killoran’s study found that search engines are significantly more helpful than most other methods. Such a connection between success with search engines and success attracting clients has made search algorithms pertinent for businesses in order to reach an audience of prospective clients on the web (2009).
Chatbots have also started gaining popularity on information platforms, for example, technical support websites, help pages, and so on. Traditional chatbot architectures depend heavily on large data sets that help process user queries using patterns and NLP. With little to no prior NLP backbone, chatbots can be expensive to develop (Paul, Latif, Adnan & Rahman, 2018). Another machine learning method to train chatbots is reinforcement learning. However, reinforcement learning algorithms are unable to structure data into datasets through patterns, thus increasing the constant need for human supervision and costing resources.
Thus, we can say that data is an important commodity for technical communication work. The nature of technical communicators’ roles has transformed significantly over time. They are tasked with finding ways to gather more data, make sense of it, and store and organize it to produce useful information, including the ability to transfer content in one format to be captured and manipulated into another (Dubinsky, 2015; Hart-Davidson, 2009) and to write content chunks that fit into a finished information product. Most technical communication work finds its way through some kind of data generated either by the organization internally or on the publicly available websites (Killoran, 2010; Johnson-Eilola & Selber 2013; Barnett & Boyla, 2016). Technical documentation is produced through the act of coordinating several data and texts, including past versions of the documentation set, a series of drafts and revisions, inputs from stakeholders (especially product developers), emails, messages resulting from project management activities, and several other sources (Johnson-Eilola, 1996). Technical communicators sometimes use tools like content management systems (CMSs) to store and structure the data and textual content. Although CMSs are not part of the content delivery process, Anderson (2007) states that they aid the process of publishing content. Technical communicators make several rhetorical negotiations while gathering data from stakeholders and cleaning it to fit into CMSs. This content is then delivered to users through help websites, chatbots, or other information tools. We can therefore say that to make the content suitable for algorithms like chatbots, information construction and delivery format along with genre selection are important responsibilities that technical communicators can handle.
The Role of Genre and Algorithms in Information Design
Genre is an important consideration in chatbot design. Technical communicators already engage with various types of documentation, such as product help systems, videos, and online forums, all of which can be viewed as genres. They fit the definition of genre as “typified communicative actions characterized by similar substance and form and taken in response to recurrent situations” (Miller, 1984). The social action that recurs in the publications genres of software documentation (Miller, 1984; Swarts, 2015) are impacted by the ways in which a user interacts with documentation types to solve problems and accomplish tasks. Awareness of document genre characteristics, especially purpose, form, and content, can be beneficial to both the technical communicator and the intended audience. While technical communicators can adhere to the genre conventions to design information architecture and content structure, users make use of standard structures to identify and work through genres to find required information (Earle, Rosso & Alexander, 2015).
In a series of studies, Freund (2015) concluded that the usefulness of specific document genres varied according to the task that the user was performing. Freund (2015) found that the perceived usefulness of specific document genres for specific task types was negatively related to a user’s level of expertise. Instead, the user’s familiarity with the subject matter of a particular project, task, or search impacted user’s information consumption behavior. Accordingly, Earle, Rosso & Alexander’s (2015) research found that the selection of genres used varied by user experience level, software product type, amount of product usage, and user role. This speaks to the challenge that technical communicators face to produce documentation to meet the needs of users in diverse contexts and also affirms the need for a healthy mix of content in specialized genres (2015), like chatbots. Technical communicators’ work includes creating content that can be reused by multiple genres through various strategies (Hart-Davidson, 2013). This work can be extended to include delivery of information in various formats, including search and chatbots.
Website search is frequently used as an interactive information tool, often supported by CMSs. In Widemuth and Freund’s (2012) review of past studies on exploratory search methods, they identified several characteristics of search: exploratory search tasks focus on learning and investigative search goals; searches are general (rather than specific), open-ended, and often target multiple items/documents; search involves uncertainty and is motivated by ill-defined or ill-structured problems; search is dynamic and evolves over time; search is multi-faceted and may be procedurally complex; and search is often accompanied by other information or cognitive behaviors, such as sense-making.
Technical writers use this knowledge to structure information so that exploratory search produces accurate results. One way of doing so is by using search engine optimization (SEO). This can be done in multiple ways, including keywords, appropriately configuring CMSs, chunking large portions of content, and so on. Search algorithms are designed to collect content from the CMS and to deliver information to users in a timely manner. Documentation frameworks like DITA (Darwin Information Typing Architecture) also help improve SEO. By using DITA, technical communicators provide short descriptions of topics, making them identifiable.
Chatbots are another method that has become extremely popular in content delivery platforms. Trade publications in the technical communication field have speculated about the role of technical communicators for developing or supporting the development activities for chatbots for quite some time. In the 2018 January issue of Intercom, Earley states that chatbots are content delivery platforms that leverage data and AI. The conventional role of writers to create content and publish it in a structured and rationalized manner has become crucial for chatbot design as well. Earley (2018) predicted that as subject experts, technical communicators are most equipped to address the content requirements of chatbots. We believe that in addition to the content responsibilities, technical communicators can do a lot more, like designing the chatbot, reviewing the data and developing questions, improving the usability of the chatbot, and building the chatbot. Despite these reasons and chatbots becoming commonplace on information and marketing platforms, very little research has been published in technical communication scholarship; most discussion is found in trade publications. As technical communicators prepare for the role of supporting AI processes through content handling and interdisciplinary collaborations, we need to develop a better understanding of audiences’ needs from chatbots and how we can use our existing knowledge to design content for evolving genres like chatbots. This research is an attempt to start that discussion.
METHODS
The purpose of this study was two-fold. The first step was to evaluate the functionality, communication, design, and effectiveness of chatbots. The second step was to analyze the efficiency of chatbots when compared to the search feature on help websites. To do so, we used an exploratory testing approach in which we examined how chatbots responded to a series of inquiries. Then, we systematically analyzed the characteristics of chatbots to gain insights on their effectiveness based on the characteristics derived through a comparative analysis with search.
We started to examine chatbot content and search content on websites of three telecommunications companies—Verizon, Sprint, and AT&T. We chose telecommunication companies because we wanted to make sure that we had an adequate sample of data. Because these companies offered similar services to customers and most of their information is publicly available online, we found that there was sufficient and comparable resemblance in the information they provided. This was important in our communication design-based study and allowed us to ask the chatbots the same questions and compare similarities, saliences, and differences in responses. Additionally, very little research exists on evaluating chatbots (Radziwill & Benton, 2017; Yu, Xu, Black & Rudnicky, 2016; Peras, 2018), and almost none of it addresses chatbot requirements from a communication design perspective. Therefore, instead of analyzing a broad range of parameters, it was important to conduct an in-depth analysis to first establish the parameters themselves.
Since chatbots’ appearances on web pages are similar to chat interfaces and the language used is semi-formal in nature, it becomes difficult to detect whether the conversation is happening with a human or chatbot. After an initial round of data analysis, we discovered that depending on where we accessed the chat, we either encountered a human agent or a chatbot. We generally found that accessing chat on the home and support pages consistently allowed us to interact with a chatbot, so we shifted focus to just the chatbot.
At this point, however, AT&T became untestable because the chatbot always required us to log in. Therefore, we removed AT&T from the study. This left us testing chatbot and search functions on only two websites—Verizon and Sprint. Another challenge that we faced is that the data, chatbot, and search algorithms were updated on a regular basis. To conduct our research, we only used publicly available data and data collection occurred from January 2019 to May 2019. Based on the information on Verizon’s website, 12 inquiries were designed that fall under three content categories: procedural, troubleshooting, or features (see Table 1).
Procedural inquiries focused on step-by-step instructions on how to accomplish a specific task. For example, “How do I activate a new line?” Troubleshooting inquiries differ from procedures in focusing on a device-related problem for which the customer desires a solution: that is, no real-time text, a hacked phone, a cracked screen, or outdated software. For example, “I think my phone has been hacked. What do I do?” Finally, feature-based inquiries focused on products or phone-related features. For example, “Are there wireless options overseas?” Inquires also ranged in complexity. Since the same queries were run across both chatbots and the sample data was collected and analyzed by both researchers, the level of complexity was not determined or documented explicitly.
Data generated through conversations with the chatbots were documented in a spreadsheet and consisted of both the inquiries and the responses to those inquiries, which were generated from both chatbots and search functions. Conversations with chatbots were preserved in two ways. Sprint’s chatbot had a transcript email feature, so we were able to collect data from conversation transcripts received over email. Since Verizon did not provide the email transcript feature, textual data from chatbot conversations were copied and pasted into the same spreadsheet. When attempting to highlight specific features within the data set like choices, prompts, or workflow paths, we took screenshots for visual representations that were saved as JPEG files. The JPEG files and spreadsheet were saved in a shared online repository. Throughout the research, we put short memos (notes) into the spreadsheet to maintain a record of preliminary findings, knowledge sharing, and collaboration.
Test Case 1: Evaluating Chatbots’ Design
In our first test with just chatbots, we accessed the chat popup from the technical support page. Then, we copied and pasted the inquiry into the chat pane. To gather as much data as possible, we conversed with the chatbot naturally to draw out the conversation for as long as possible. The conversations ended when the chatbot requested that we to log in or if the chatbot transferred us to a human agent.
Test Case 1 used all 12 inquiries with Verizon and Sprint’s chatbots, and we tracked how information was provided to the researchers. Using all 12 inquiries was important to ensure we had enough data for analysis.
We documented all chatbot responses in the shared spreadsheet as either being “Link Providing” or “Chatbot Providing.” Link Providing responses meant the chatbot was unable to provide information in the conversation and instead provided a link to take us to the information we needed. Chatbot Providing responses meant the chatbot was able to respond in the chat pane with the information we needed. We also recorded additional notes for interesting and unexpected observations. The chatbots were very responsive, so the time it took for the chatbot to respond was not recorded as part of this test.
Test Case 2: Comparing Chatbots to Website Search
We then conducted a comparative analysis between chatbots and search to investigate how these information tools perform differently and how they can impact users’ information-finding experiences on telecommunication companies’ websites. For this test, we used 5 of the 12 total inquiries in Table 1 (see Table 2). Unlike chatbots, a website’s internal search tool can display results even if the user is familiar with only a few keywords and can articulate the problem with few words. Therefore, instead of using fully formed questions, we used only keywords or key phrases for both search and chatbots.
We put our inquiries into the chatbot space or chat pane after the chatbot asked for them. For example, we used the Sprint chatbot on the Sales web page. The Sprint chatbot began with the message, “Hi, I’m a Sprint sales specialist. Would you like any help today?” which shows a greeting followed by a question. We typed our keyword inquiry into the message space after that first message from the chatbot. The keywords we used are in Table 2.
We reported results on the shared spreadsheet. The results were as follows:
- Chatbot results were documented based on four main aspects: the time required or how long it took to get comprehensive information on solving the issue, messages relayed while the researcher (user) was waiting, whether the information provided by the chatbot was accurate, and whether the information was acquired through the chatbot only without human intervention.
- Search results were documented based on the number of search keywords used: time required
to acquire the desired and accurate information, efficiency of search reported as the position of an accurate result link in the series of links produced by the search query, and the delivery format of help information topic (e.g., video, FAQ).
 RESULTS
RESULTS
In our study, we first did some preliminary testing to get a feel for what we might expect as well as to address any potential issues. Then we conducted our full testing. In this section, we first describe our preliminary findings, which informed our full testing. Then we discuss the findings for both of our studies—Test Case 1 and Test Case 2. The next section describes the heuristic that was developed from these results.
Preliminary Findings
Before the official testing, we performed preliminary testing with three inquiries, one from each category, to make sure they yielded valuable data to proceed with this research. The results of the preliminary testing were interesting. We generally found that depending on where users select the chat button on the website, they will encounter either a human agent or a chatbot. Human agents were commonly found when chat was accessed from product pages or sales-related pages, whereas chatbots were accessed from support and troubleshooting pages. Because the study is focused on chatbots, we used the chatbots on the home and support pages, and we avoided conversations with anyone identified as an “agent.” This shift removed AT&T from the study because AT&T’s chatbot seemed to always redirect us to the agents. The second reason we dropped AT&T from the study is that their support chatbot always required the user to log in using an AT&T account no matter the inquiry. Since we were using only publicly available information for our study, we could not proceed with using data provided by AT&T’s chatbot. It is also worth noting that there was a gap of a few weeks between preliminary testing and full testing. During that time, we determined that the chatbot software was updated based on differences in design and responses. All inquiries tested during preliminary testing were retested during official testing.
Findings 1: Chatbot Usability and Information Design
The findings from Test Case 1 led us to consider aspects of usability and information design when creating support chatbots. As technical communicators, we know that users access information online with intention, looking for specific pieces of information (Krug, 2014), and that mindset was taken into consideration when engaging with the chatbot and analyzing the data.
Chatbot inquiry input
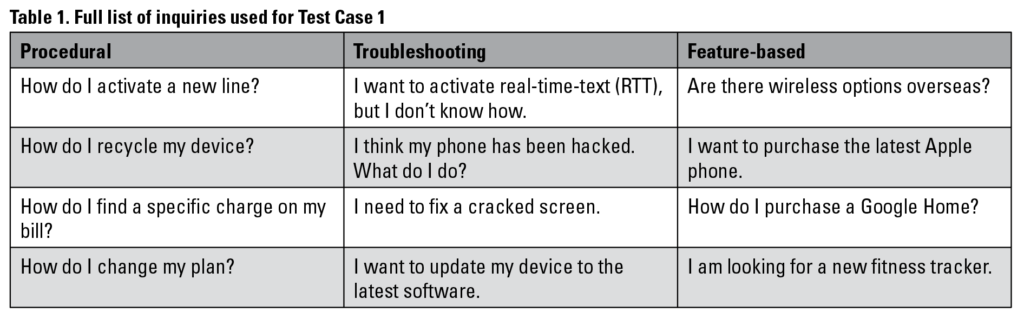
We always started from the support page for both websites (Sprint and Verizon). We used the 12 inquiries (see Table 1) to simulate a natural conversation with the chatbot for as long as possible before the chatbot required us to log in or wanted to transfer us to a human agent. The input method for each chatbot was different and made a significant difference in our interactions with the chatbot. Verizon provided links to suggested topics as well as an option to enter text into a free-form text box. Sprint, on the other hand, was inconsistent in the initial interaction with the chatbot. Sometimes, the chatbot asked us for our personal information and allowed us to enter text into a free-form text box. Other times, we had to first choose from a list of categories (see Figure 1) for our inquiry before we could enter our inquiry. Categories helped users pick a topic that their search query belonged to. For example, “View your bill” and “Make payment” were both related to the user’s bill payment; both took users directly to the web page where these actions were to be performed instead of a help page that provided information to users on how to do it. For both chatbots, we started with the inquiry as written in Table 1, but as the conversation progressed, we also changed our phrasing and keywords to try to elicit the response we needed.
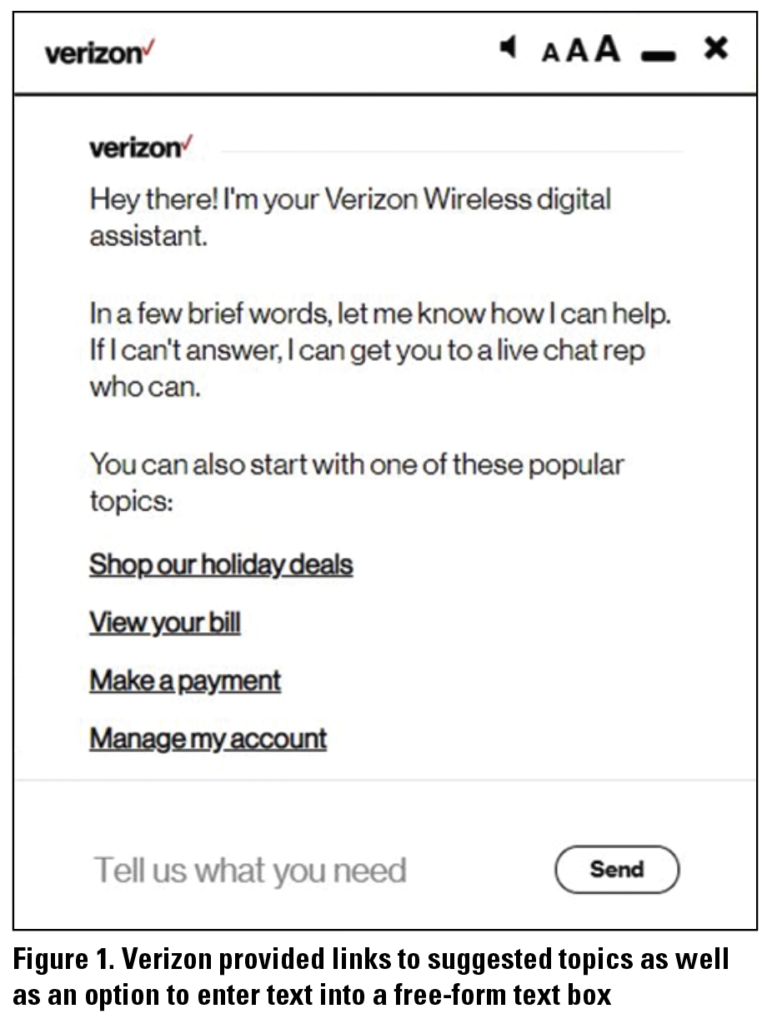 Figure 1. Verizon provided links to suggested topics as well as an option to enter text into a free-form text box
Figure 1. Verizon provided links to suggested topics as well as an option to enter text into a free-form text box
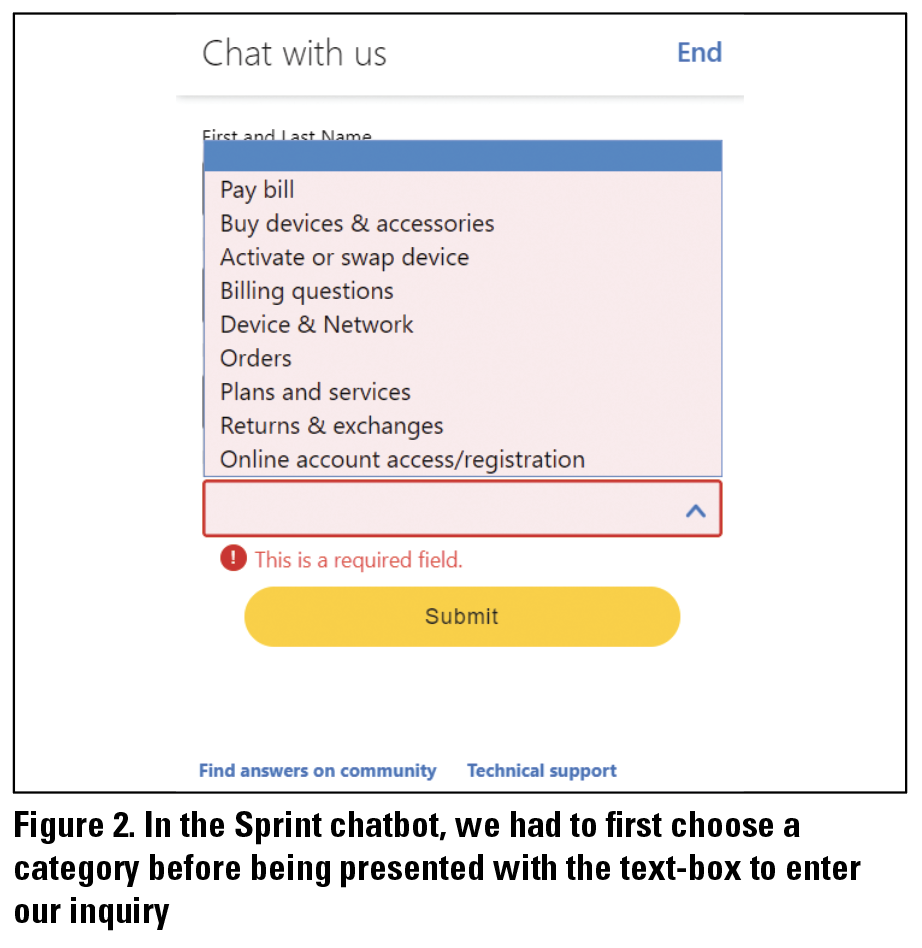 Figure 2. In the Sprint chatbot, we had to first choose a category before being presented with the text-box to enter our inquiry
Figure 2. In the Sprint chatbot, we had to first choose a category before being presented with the text-box to enter our inquiry
 Figure 3. The Sprint chatbot required us to enter our personal information before giving access to the free-form text box
Figure 3. The Sprint chatbot required us to enter our personal information before giving access to the free-form text box
Chatbot response and delivery
Structure of response. After submitting the initial inquiry, we had a natural conversation with each chatbot to help articulate our inquiry in a way that matched the chatbots’ interpretation of the inquiry. This happened when the chatbot either rephrased our inquiry asking to confirm that the question was accurate or when it provided several suggestions for information (including hyperlinks to content topics). Some inquiries were Chatbot Providing, which meant the chatbot was able to give us the answer directly in the chatpane. This usually included descriptive text explaining the answer to the inquiry. For example, the Verizon chatbot instructed us on how to upgrade a phone to the latest software. Most responses were Link Providing, where the chatbot provided an external link to a particular topic or page with the information we were looking for. Verizon’s chatbot generally responded with Link Providing responses, and when we clicked on the external link, the chat pane stayed open to ensure we did not lose the conversation despite moving to a different webpage.
![]()
Figure 4. Example of Verizon’s chatbot providing a link in the chatpane “Let’s go”
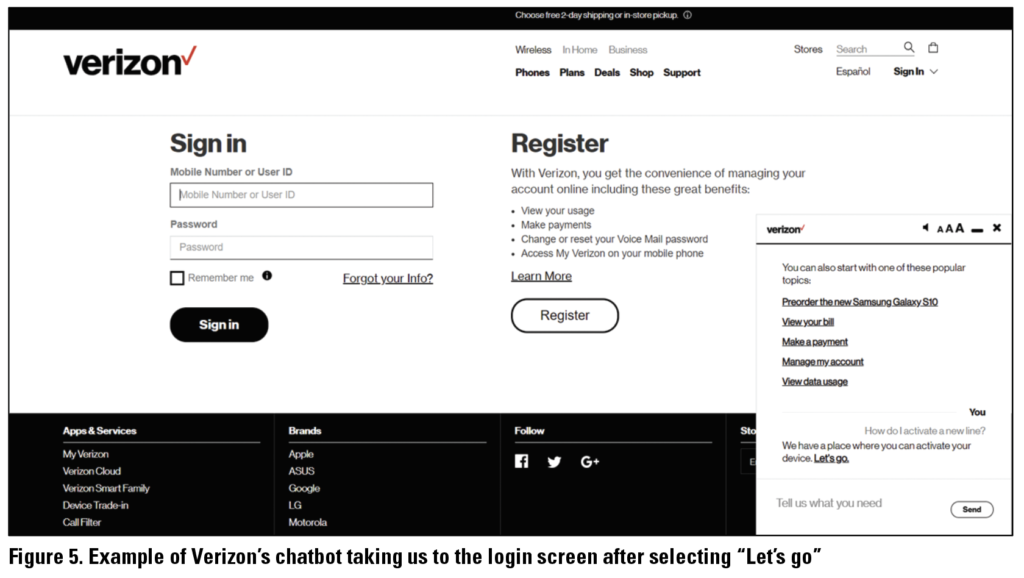
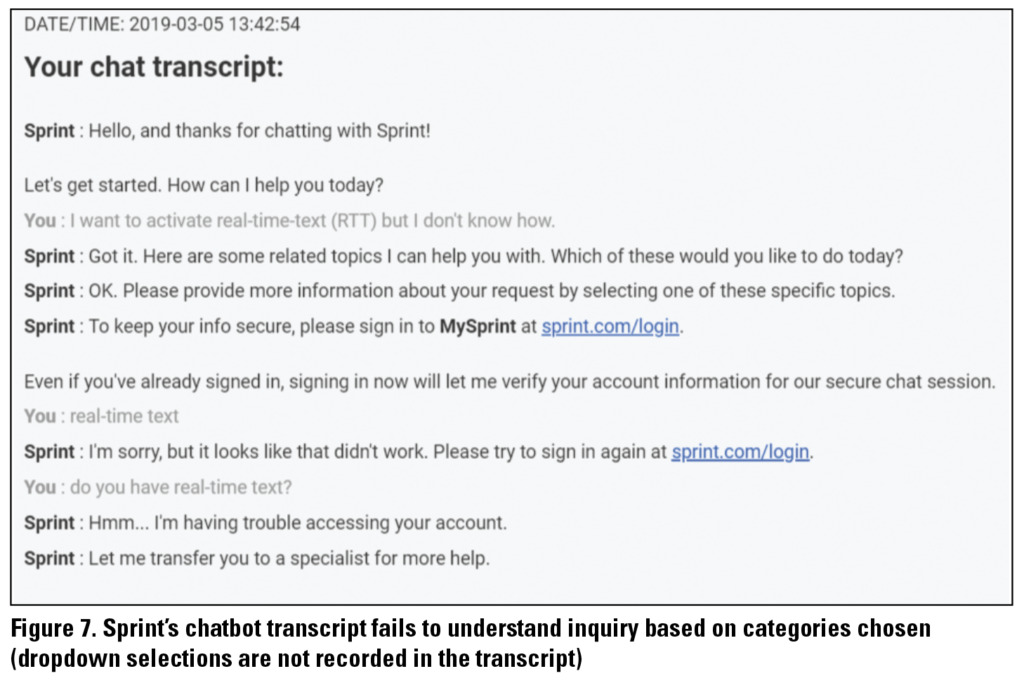
It was harder to get responses from Sprint’s chatbot because it forced us to use predetermined categories such as “Activate or swap device,” “Billing questions,” and “Device & Network.” Some of our selected inquiries (see Table 1) fit the categories like “Activate or swap device,” while in most others, it was difficult to determine which category they would potentially belong in. For example, when asking the Sprint chatbot about Real Time-Text, despite being able to enter free-form text, the chatbot still forced us to “Select a Topic” that attempted to categorize the inquiry. Unfortunately, the topics suggested did not fit, so we selected “Something Else” (see Figure 5), which allowed us to select from a wider but still limited list of options from a dropdown that also did not fit the inquiry. To proceed to a conversation with the chatbot, we selected what we thought were the best options, “Plans or add-on services” and then “Learn about service add-ons” (see Figure 5). However, when we were able to hold a conversation with the chatbot, it still did not fully understand our inquiry. We changed the entry to keywords and different phrasings to no avail. This is an example where the categories restricted our interactions negatively with the chatbot and did not help resolve our issue once we were able to enter free-form text to chat with the chatbot.
 Delivery format. As described earlier, the chatbot responses were either Chatbot Providing or Link Providing. Sometimes the chatbot provided categories or topics to choose from as a way to help narrow the conversation before allowing free-form text entry, and sometimes the chatbot allowed us to enter free-form text into the chat pane from the beginning. We then conversed with the chatbot and rephrased or reentered inquiries as needed.
Delivery format. As described earlier, the chatbot responses were either Chatbot Providing or Link Providing. Sometimes the chatbot provided categories or topics to choose from as a way to help narrow the conversation before allowing free-form text entry, and sometimes the chatbot allowed us to enter free-form text into the chat pane from the beginning. We then conversed with the chatbot and rephrased or reentered inquiries as needed.
Accuracy. The chatbot confirmed with us whether or not the response was what we were looking for after each response. When the chatbots gave us an answer to our inquiry (either as a Chatbot Providing or Link Providing response), the answer may not have been accurate at the beginning. After a little back-and-forth, all of the responses were accurate (100 percent). The links properly took us to the information we were looking for and answers given by the chatbot in the chatpane were able to resolve problems posed through the inquiries. That being said, accuracy here does not mean success in information retrieval. If the chatbot was unable to provide the response, rather than emphasize or link to incorrect information, the chatbot would transfer us to a human agent. Overall, Verizon was generally able to answer most questions without transferring us to an agent, whereas Sprint was essentially unable to answer any inquiry and had to transfer us to an agent for most of the inquiries.
Findings 2: Differences and Similarities Between Search and Chatbots
A comparison between the information tools—search and chatbots—on the telecommunication companies’ help websites revealed several differences in the way these tools accepted information-related queries and the formats in which they delivered information solutions. The following sections describe our observations from our data analysis in the second test case.
Search and chatbot inquiry input
To input an inquiry in search, we looked for a search icon on the home page of both websites (Sprint and Verizon). We used the inquiry keywords for the search (see Table 2). For chatbots, we used the keywords in place of a question. For example, to inquire about recycling the device, we used the keyphrase “Recycle my device.” Both tools were similar in terms of understanding keywords. In both tools, keyword inquiries were followed by relevant information topics. However, the displayed results differed in multiple ways.
Search and chatbot response and delivery
Structure of response. Chatbots use a back-and-forth messaging system to provide information or help topics to users. Once a query was entered in the chatbot’s message box, the chatbot responded with the solution to the inquiry or asked additional questions to get more information about the query from the user. While the chatbot algorithm processed the inquiry, a message such as “Agent is typing…” was displayed. For four out of the five queries, both chatbots asked for additional details. For example, for the inquiry “New line” the chatbot asked more information about the plans, number of lines, type of phone, etc., before it displayed information (solution) about the plans available to get a new line.
The search took an equal number of steps for this inquiry. The support web page on the site provided a list of topics to obtain help on this topic. However, we had to make appropriate selections to go to the page that displayed the plans communicated by the chatbot. While chatbot conversations asked us for our choices in the form of inputs, in the search results, we had to navigate through topics and choose the appropriate ones to gain information. If the choices did not produce results, the chatbot repeated the question; whereas, in search, we had to go back manually to the point where we started navigation by clicking the browser’s back button. After providing the necessary information, the chatbot asked us whether we had other questions before signing off.
Time until accurate response. For this test, we measured accuracy based on whether the response to inquiries provided step-by-step instructions on solving problems stated by inquiry keywords (see Table 1). For search, the time required was less than one minute if we were able to make correct choices among the links displayed. Each chatbot inquiry took at least two minutes for all the messages to be relayed and responses to be received.
Accuracy. Search was more accurate in providing help content than chatbots. We were able to get help information for all inquiries for Verizon and four out of five inquiries for Sprint in less than three web pages linked through the search results section. The Sprint chatbot could only answer one out of five inquiries, and the Verizon chatbot could answer four out of five.
Delivery formats. Another significant difference between chatbot and search responses was the format of delivery. Search provided help information through links to web pages that could be printed or converted to PDF using browser features. Sprint also provided a feature to share the content via social media. Search page links can also be saved using the bookmark features on browsers in case we wanted to go back to the content later. To save chatbot conversations for Verizon, we had to copy and paste the entire conversation to save it for local (later) use. Sprint’s chatbot provided the email feature to save conversations. If we chose email, the conversation was emailed to us in a few minutes.
DISCUSSION
Despite the increasing popularity of AI, chatbots, conversational interfaces, and deep learning, chatbot research is still largely missing from the technical communication academic journals. On the other hand, trade publications have been actively trying to find answers to the questions: “Is there nothing we, as technical communicators, can do? And is there something we should do?” (Ames, 2019). The July/August 2019 issue of Intercom, dedicated to content design and development for machine delivery, was an attempt to document technical communicators’ perspectives surrounding this new demand and what we can do to address it. Andrea Ames (2019), contends that technical communicators have the skills necessary to embrace writing for these genres as well. We need to use our “advocacy, research, strategy, architecture, design, development, and delivery skills to create the right content and present it exactly when and where the right people need it” (p. 4). The primary differences between traditional technical writing and writing for chatbots point to storage formats, size of content chunks, and delivery medium. Although technical communicators are not yet often involved in writing for chatbot interactions, we should be. Technical communicators are capable of studying interactions by considering what is humanistic about technology use based on an understanding of audiences who would be engaging with it or through it (Ranade & Swarts, 2019). Thus we can say that technical communicators can adapt these skills and fulfill content requirements of genres like chatbots.
Our exploratory study looked closely at chatbots to learn more about interactions, types of content, delivery, and usability of chatbots. Additionally, studying the differences between chatbots and traditional tools like search further helps focus on the differences in the characteristics of these information tools. The findings partially address questions about how the work and skills of technical communicators can be extended (not replaced) while writing for machines when incorporated into the design and development of information tools. In the following sections, we draw conclusions from our findings, especially about the usability of chatbots and their information design.
Study Limitations
Our study has several limitations. First, we conducted the study in the Spring of 2019 over the course of several months. This is a small timeframe, and the chatbots we used could be updated and improved since then, which would cause variation with our results. Additionally, we chose very specific, existing chatbots rather than creating a chatbot ourselves or doing a larger, random sampling of chatbots. This means our data set is also small and specific to the telecommunications industry. While a smaller data set might seem limiting, our choice gave us better control over the information inquiries—we wanted to test the chatbots and search without worrying about whether or not the information existed or was reliable. This enabled us to focus on the chatbot and search results without questioning the reliability of the information. This is why despite some limitations, we feel that our results and the heuristic we developed provide a good starting place for both practitioners and researchers to begin considering chatbot information design.
Desirable and Undesirable Characteristics of Chatbots
We observed that the chatbot feels flexible and helpful when it has these characteristics:
- Ability to enter free-form text into the chat pane,
- Back-and-forth conversation that allowed the chatbot to drill down to the content we were looking for,
- Specificity of information provided in the chat pane,
- Functionality to open redirects in another tab (navigating to links provided by the chatbot did not exit us out of the chat pane), and
- Ability to automatically record conversations.
We also observed that the chatbot feels inflexible or unhelpful when:
- Free-form input is not allowed and/or there are topic restrictions based on categories,
- Answers vary and/or are inconsistent, and
- There is lack of automation for recording conversation.
Verizon’s chatbot mostly embodied desirable characteristics. With Verizon, we were able to enter free-form text into the chat pane, have a conversation where the chatbot was able to determine the content we were looking for, the chatbot used both Chatbot and Link Providing responses, and link redirects were smooth without exiting the chat pane. However, we were not able to record the conversation easily through email or save the conversation as a PDF.
Sprint’s chatbot mostly embodied undesirable characteristics. With Sprint, we were restricted to making selections from limited categories, and free-form text entry was not useful because we were immediately directed to choose a category afterwards. Additionally, Sprint’s responses were varied and inconsistent, and we were not able to have a fluid conversation with the chatbot. These elements essentially made the chatbot unusable. However, we were able to save a transcript of the conversation through email, although category choices were not recorded in the transcript.
Neither chatbot was perfect or fit either description fully. In both chatbots, we would have preferred seeing more Chatbot Providing responses. This is seen as more usable because it means the user does not have to go extra places on the site or think about where to find the information they need (Krug 2014). Sprint’s chatbot revealed the problems of only using a category approach—the responses and taxonomy were so limiting that the chatbot was unable to answer most of the inquiries. Verizon’s chatbot also had categories, but they were at the beginning of the conversation and were optional for the user to select. This indicates that categories can be problematic if they are the primary or sole input method, especially without appropriate taxonomy and metadata infrastructure to support it.
Comparing Search to Chatbots
In the comparative analysis between search and chatbots, we observed that search was more effective since search results were returned faster than chatbots’ responses with fewer interactions and with more accuracy. However, chatbots can become more efficient over time with the use of proper architectures like NLP. The cost to build these architectures, including other requirements and returns on investment, must be closely compared before making decisions on which information tool to deploy on information websites.
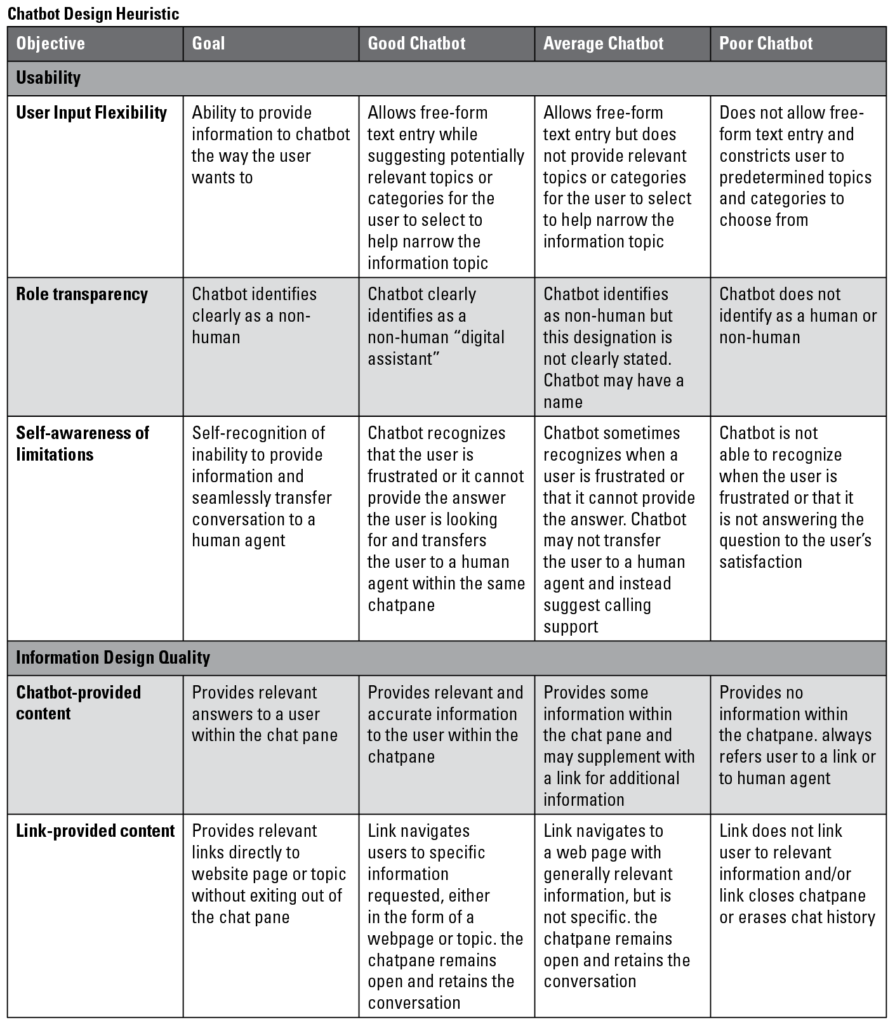
Chatbot Design Heuristic
Based on the findings from our studies, we created a chatbot design heuristic (see the Appendix for the tabular format). Researchers and practitioners can use this heuristic to help design, develop, and test chatbots from a high level. The heuristic is designed to help technical communicators to think about overall usability, information design, and accessibility.
Heuristic: chatbot usability
The usability heuristic focuses on three categories: user input flexibility, role transparency, and self-awareness of limitations.
- User input flexibility focuses on the ability to provide information to the chatbot the way the user prefers. Essentially, this is allowing the user to provide free-form text entries that may be accompanied by suggested topics from the chatbot.
- Role transparency is making sure the chatbot identifies as a non-human entity. This is important for setting users’ expectations as well as good ethical practices. If the chatbot identifies as non-human, users may be more forgiving of the chatbot’s limitations and will also be able to accurately discuss the chatbot’s suggestions if the issue is escalated to a human agent. Additionally, as automated assistants begin to enter our lives more pervasively, we believe it is significant to draw the line in identification between humans and non-humans as a good ethical practice.
- Self-awareness of limitations is the chatbot’s ability to recognize when they are not able to address the user’s problem and is able to seamlessly transfer the user to a human agent. The chatbot should be able to recognize when a user is frustrated or when all options available to the chatbot are exhausted as a sign that the chatbot is unable to assist the user and needs to send the user to a human agent.
Heuristic: information design quality
The information design heuristic focuses on three categories: chatbot-provided content, link-provided content, chatbot conversation responsiveness.
- Chatbot-provided content means the chatbot is able to provide direct, concrete answers for the user within the chat pane. This is important because it means the user is able to obtain answers directly and efficiently, which is the entire goal for implementing a chatbot.
- Link-provided content means the chatbot directs the user with a link to a website or topic without exiting the chat pane. While chatbot-provided content is preferable, sometimes a link to a website or a specific topic is more appropriate. In these cases, links should go directly to specific locations on a web page that are relevant to the user (topic), unless the entire web page is relevant, such as a product-specific page.
- Chatbot conversation responsiveness refers to the chatbot’s ability to converse with the user fluidly and, through conversation, determine what the user is looking for and deliver the information they need. The chatbot should be able to go back and forth with the user effectively to narrow the conversation and request.
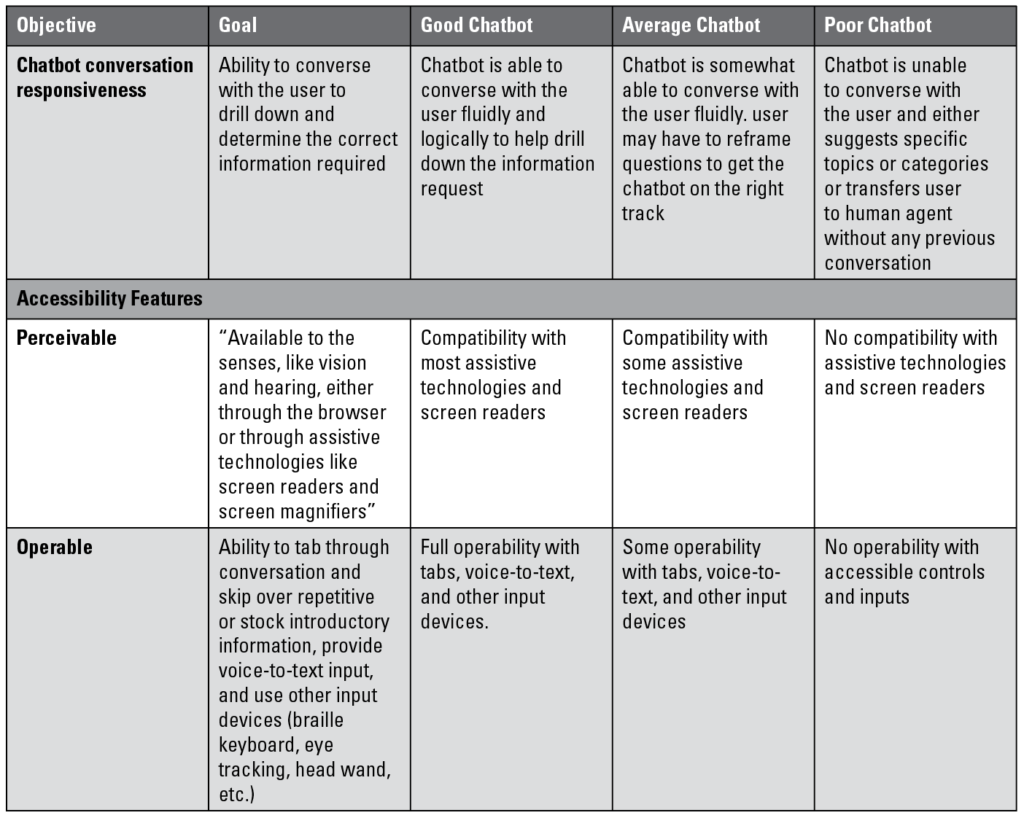
Heuristic: accessibility features
While accessibility was something we could not test, we felt it was important to include in the heuristic to ensure inclusive design. The two heuristic categories are perceivable and operable.
- Perceivable refers to compatibility with auditory senses and practically focuses on compatibility with screen readers and other assistive technologies. This is significant considering how chatbots may soon be the primary form of support communication.
- Operable refers to various ways users can engage with the chatbot. This includes the ability to tab through the conversation, skip over repetitive or stock content, use voice-to-text input, and use other input devices, such as a braille keyboard, eye-tracking software, hand wand, etc.
CONCLUSION
Throughout our study, we sought to understand the usability design of chatbots and how chatbots compare to search. Based on the findings in the first test, conducted with just chatbots, we created a high-level design heuristic as an initial baseline into understanding how to consider chatbot usability, information design, and accessibility when designing a chatbot. The findings of the second test compared chatbots to search and considerations for preferring one over another.
Technical communication practitioners have several takeaways from the study. First, leveraging and integrating with existing content and CMS is important when planning chatbots’ information design. This will reduce duplicated content and support content reuse. Second, ensuring this content has proper metadata tagging through a controlled taxonomy will make it easier for the chatbot to recognize keywords associated with particular topics and smaller pieces of content. This is critical for overall chatbot implementation, whether using NLP or relying solely on existing content.
This study also has several pedagogical implications. First, chatbots require base knowledge in other areas, such as information architecture, content management, and content strategy to ensure good information design planning (this ties with the practitioner takeaways), which helps the rhetorical negotiations and decision-making process while developing and publishing content. Second, audience analysis is important to understand the usability and conversation flow of the chatbot and forces students to consider questions such as “Does the chatbot always need a personality?” and “Where is the chatbot getting its information from?” Lastly, curricula should identify the use cases where search is more optimal for the user journey as opposed to chatbots. This enables students to recognize the strengths and weaknesses of delivering information on both information tools. Additionally, a rhetorical study of the chatbot genre can highlight other advantages and limitations of using chatbots for user advocacy and inclusivity purposes.
We hope that future research will pursue some of these ideas and use our heuristic to evaluate chatbots from other sectors and for other purposes. We specifically examined support chatbots, but medical and sales chatbots are also prevalent chatbot implementations. We hope to expand the heuristic by testing diverse chatbots and continue to iterate and refine the heuristic with larger datasets. This study also paves the way for pedagogical research to look at how technical communicators can extend their work to add value to this new genre of communication.
Acknowledgments:
The authors would like to thank Dr. Huiling Ding for her help with this research. The readings and data preparation for this research began in her directed research class at NC State University during Spring 2019.
REFERENCES
Ames, A. (2019). A note from the Editor. Intercom, July/August, 4–5., R. (2007). The rhetoric of enterprise content management (ECM): Confronting the assumptions driving ECM adoption and transforming technical communication. Technical Communication Quarterly, 17(1), 61–87. https://doi.org/10.1080/10572250701588657
Barnett, S., & Boyle, C. (Eds.). (2016). Rhetoric, through everyday things. University of Alabama Press.
Brin, S., & Page, L. (1998). The anatomy of a large-scale hypertextual web search engine. Computer Networks and ISDN Systems, 30(1–7), 107–117.
Diakopoulos, N. (2016). Accountability in algorithmic decision making. Communications of the ACM, 59(2), 56–62. https://doi.org/10.1145/2844110
Dubinsky, J. (2015). Products and Processes: Transition from “Product Documentation to … Integrated Technical Content.” Technical Communication, 62(2), 118–134.
Earle, R. H., Rosso, M. A., and Alexander, K. E. (2015). User preferences of software documentation genres. In Proceedings of the 33rd Annual International Conference on the Design of Communication (SIGDOC ‘15). Association for Computing Machinery, New York, NY, USA, Article 46, 1–10.
Earley, S. (2018). AI, chatbots and content, oh my! Intercom, April, 12-14.
Freund, L. (2015). Contextualizing the information-seeking behavior of software engineers. Journal of the Association for Information Science and Technology, 66(8), 1594–1605.
Gillespie, T. (2014). The relevance of algorithms. In T. Gillespie, P. J. Boczkowski, & K. A. Foot (Eds.), Media Technologies, 167–194. https://doi.org/10.7551/mitpress/9780262525374.003.0009
Hart-Davidson, W. (2009). Content management: Beyond single-sourcing. In Digital literacy for technical communication (pp.144–160). Routledge.
Hart-Davidson, W. (2013). What are the work patterns of technical communication. Solving problems in technical communication, 50–74.
Hughes, M. (2002). Moving from information transfer to knowledge creation: A new value proposition for technical communicators. Technical Communication, Washington, 49(3), 275–285.
Jenkins, H. (2004). The cultural logic of media convergence. International Journal Of Cultural Studies, 7(1), 33–43.
Johnson-Eilola, J. (1996). Relocating the value of work: Technical communication in a post-industrial age. Technical Communication Quarterly, 5(3), 245–270. https://doi.org/10.1207/s15427625tcq0503_1
Johnson-Eilola, J., & Selber, S. A. (Eds.). (2013). Solving problems in technical communication. The University of Chicago Press.
Killoran, J. B. (2009). Targeting an audience of robots: Search engines and the marketing of technical communication business websites. IEEE Transactions on Professional Communication, 52(3), 254–271.
Killoran, J. B. (2010). Writing for robots: Search engine optimization of technical communication business web sites. Technical Communication. 57(2), 1611–81.
Killoran, J. B. (2013). How to use search engine optimization techniques to increase website visibility. IEEE Transactions on Professional Communication, 56(1), 50–66.
Krug, S. (2014). Don’t make me think! Revististed: A common sense approach to web and mobile usability. 2nd edition. New Riders Publishing.
Laursen, A. L., Mousten, B., Jensen, V., & Kampf, C. (2014). Using an AD-HOC corpus to write about emerging technologies for technical writing and translation: The case of search engine optimization. IEEE Transactions on Professional Communication, 57(1), 56–74. https://doi.org/10.1109/TPC.2014.2307011
McCarthy, J. E., T. Grabill, J., Hart-Davidson, W., & McLeod, M. (2011). Content management in the workplace: Community, context, and a new way to organize writing. Journal of Business and Technical Communication, 25(4), 367–395. https://doi.org/10.1177/1050651911410943
Miller, C. R. (1984). Genre as social action. Quarterly Journal of Speech, 70(2), 151–167. https://doi.org/10.1080/00335638409383686
Oxford Dictionaries. (n.d.) Chatbot in Oxford Dictionaries in English. https://en.oxforddictionaries.com/definition/chatbot
Paul, A., Latif, A. H., Adnan, F. A., & Rahman, R. M. (2018). Focused domain contextual AI chatbot framework for resource poor languages. Journal of Information and Telecommunication, 0(0), 1–22. https://doi.org/10.1080/24751839.2018.1558378
Peras, D. (2018). Chatbot evaluation metrics. Economic and Social Development: Book of Proceedings, 89-97.
Radziwill, N. M., & Benton, M. C. (2017). Evaluating quality of chatbots and intelligent conversational agents. Retrieved from http://arxiv.org/abs/1704.04579
Redish, J. (1995). Adding value as a technical communicator. Technical Communication 42(1), 26–39.
Ranade, N. & Swarts. J. (2019) The humanist in information centric workplaces. Communication Design Quarterly. 7(4), 17–31.
Reynolds, M. (2016, March 31). Microsoft is betting that bots “are the new apps.” Retrieved from https://www.wired.co.uk/article/microsoft-build-bots-ai-cortana-keynote-conference
Swarts, J. (2015). Help is in the helping: An evaluation of help documentation in a networked age. Technical Communication Quarterly, 24(2), 164–187. https://doi.org/10.1080/10572252.2015.1001298
Taylor, C. (2018, March 28). Structured vs. Unstructured Data. Retrieved from https://www.datamation.com/big-data/structured-vs-unstructured-data.html
Tredinnick, L. (2017). Artificial intelligence and professional roles. Business Information Review, 34(1), 37–41. https://doi.org/10.1177/0266382117692621
Wildemuth, B. M., & Freund, L. (2012). Assigning search tasks designed to elicit exploratory search behaviors. Proceedings of the Symposium on Human-Computer Interaction and Information Retrieval – HCIR ’12, 1–10.
Yu, Z., Xu, Z., Black, A. W., & Rudnicky, A. (2016). Chatbot evaluation and database expansion via crowdsourcing. In Proceedings of the chatbot workshop of LREC, 63, 102.
ABOUT THE AUTHORS
Nupoor Ranade is a Ph.D. Candidate in Communication, Rhetoric, and Digital Media at North Carolina State University, and an incoming Assistant Professor at George Mason University. Her research focuses on audience analysis, digital rhetoric, user experience, and information design, primarily in the field of technical communication and artificial intelligence. Her background, work experience, and partnerships with the industry help her bridge research gaps. She then brings that knowledge to her pedagogical practices. She is available at nranade@gmu.edu.
Alexandra Catá is a PhD Student in North Carolina State University’s Communication, Rhetoric, and Digital Media program focused on intersections between technical communication and video game studies/design. She is interested in how game development and design cultivate user experiences and how rhetorical discourses are shaped between game developers and players. She has almost a decade of experience as a technical writer working on IT, software, and hardware documentation, most recently for Epic Games. She is available at ascata@ncsu.edu.
Appendix
Manuscript received 28 May 2020, revised 7 August 2020; accepted 19 September 2020.

