By Nupoor Ranade
Abstract
Purpose: This research paper explores the following phenomena that impact content strategy in technical communication (TC): 1) understudied user analysis methods that reveal users’ information seeking behavior, 2) changes in infrastructure design for innovative user research practices, 3) skill sets required by technical communicators to carry out content strategy tasks.
Methods: Methodologically, the article reports findings from 19 interviews conducted with TC practitioners who hold titles such as technical writer, content strategist, information developer, information architect, and documentation manager.
Results: The interviews revealed more than 13 practices/methods in which users’ interactions resulted in data that provided more information about them which impacted the design of content platforms. I classified the findings into 4 main categories of users’ interactions that hold valuable insights about users’ information consumption behavior. These insights that can be used to make informed content strategy decisions are lost if the data is not carefully processed.
Conclusion: This paper demonstrates how user interactions can inform research on content strategy in TC and how it impacts the processes of users, as well as the impacts on existing roles of technical communicators. I argue that we need to be more purposeful about analyzing users’ interactions that produce data and design infrastructures to support interactions as part of an organization’s content strategy goals. My future work will focus on how issues such as privacy, surveillance, and incentivization can be handled in situations where users’ information is used for audience analysis purposes.
Keywords: Content Strategy, User Research, User Generated Content, Practitioner Roles
Practitioner Takeaways
- Technical communicators can use methods discussed to develop new methods and infrastructures to learn about their audiences.
- The methods proposed will allow for participatory frameworks and decentralization allowing diverse audiences to participate in content management thus promoting social justice through content strategy decisions.
- The infrastructures will help build collaborations and partnerships across multidisciplinary organizational stakeholders and contribute to effective problem solving through content strategy and development.
Introduction
The technical communication (TC) field has undergone various shifts over the years owing to new approaches to developing information (Albers, 2003; Carter, 2003; Rude, 2009; Swarts, 2011), technology adoption and diffusion (Andersen, 2014; Dayton, 2006), and the nature of work activities such as being networked (Hart-Davidson et al., 2012; Swarts, 2010) and distributed (Hart-Davidson, 2009; Salvo, 2004; Whittemore, 2008). Some changes that were documented along the way include processes such as topic-based authoring, minimalism, single-sourcing, structured authoring, and technologies such as XML, component content management, static site generators, and Git. Another function, a part of technical communicators’ job roles, that brought about a shift in the field was access to user data that helped technical communicators learn more about their users’ needs and expectations from content (Turns & Wagner, 2004; McGuire & Kampf, 2015). Audience analysis has always been a big part of technical communicators’ jobs. However, with increased access to users’ input into online documentation platforms through features like comments, like and dislike buttons, social media posts, and discussion forums, technical communicators can evaluate their audiences at a more precise level leading to customization and personalization of documentation (Andersen, 2014; Breuch, 2018). Such audience insights not only help us create customized content, but also help with decisions on content design and therefore content strategy.
Users’ inputs or contributions play a key role in content strategy, especially in product documentation spaces. In 2002, Steehouder argued about the importance of learning from users to set up documentation such that it appears more like a communication dialogue rather than an information site. To design documentation in that manner, we need to evaluate users’ requests and design the responses as answers to users’ specific questions (Steehouder, 2002). In order to do this, technical communicators started analyzing user requests. Most studies that describe such analyses did so by analyzing content created by users (Barton & Heiman, 2012; Cooke, 2021; Swarts, 2015) such as reactions on existing documentation platforms, feedback, and comments (Ranade & Swarts, 2022; Doan, 2021; Gallagher & Holmes, 2019). All these methods work with content that is always visible and available for analysis.
Some newer methods that record users’ interactions with documentation platforms are not always visible. For example, the Documentation as Code (DaC), popularly known as the docs-as-code approach, is a revolutionary methodology in which technical writers and other organizational stakeholders, including users, can contribute and maintain the product documentation platform using the same processes and tools as software code development (Gentle, 2017). Since contributions happen on the back end, or the tools interface, end users cannot view other users’ contributions until they themselves decide to make a change. This hides some user inputs and along with the needs of those users. Another example is users’ activities recorded in the form of web analytics data. Based on browser settings, different data gets recorded from every users’ browser. This data is invisible to end users and sometimes to the technical communicators too (depending on each organization’s policies). The data hides characteristics of users that challenge the process of tailoring responses to users’ specific needs. I believe that we need to be more intentional about exploring such users’ interactions through conscious interventions and strategic methodologies.
In this article, I term such users, whose characteristics get hidden, as “hidden users.” Although data gets generated due to their interactions, most times it remains invisible, thus challenging the process of user analysis. For example, a user’s information seeking behavior on Google Search is recorded through interactions like entering search terms (keyword choices) and the decisions they make about which result to choose from a list (navigation behavior) to solve their problem speedily. Both data points are unique—the keyword choices depend on the user’s background and the navigation behavior depends on the specificity of the problem they are facing. Because these interactions are not visible (unless someone is more intentional in analyzing the behavior of a particular user among hundreds or millions), the interactions remain unknown. I have termed such interactions that generate data as invisible interactions.
While technical communication scholars have studied audience contributions to platforms such as user forums (Swarts, 2007; Frith, 2017), feedback on public websites such as blogs (Gallagher, 2020), and interactions with social media posts (Breuch, 2018), there is very little research on invisible interactions. Such interactions can provide several insights about audiences, especially in online content deployment spaces. Hidden users and hidden users as part of hidden communities are studied in other disciplines like communication networks and information systems (such as Blekanov et al., 2021; Burrell, 2012; He et al., 2015; Yoshida, 2013). Models such as He et al.’s (2015) that use web analytics to assess audiences and thereby inform an organization’s content strategy plans have been widely used for quite some time. He et al.’s competitive analytics framework provides a process for identifying highly engaging topics in social media content. The framework not only interprets the verbal content, but also helps note invisible interactions to identify users’ sentiments that are then used to identify patterns and craft strategic recommendations for new content development (He et al., 2015; Kordzadeh & Young, 2022). To expand such models, media scholarship has, in fact, encouraged participation from users as a way to decentralize and empower users (Bruns, 2008; Spears & Lee, 1994; Westlund & Lewis, 2014) for more than two decades. This paper borrows literature and methods from the fields of technical communication and media studies to analyze new sites of study that allow exploring hidden users, invisible interactions, and their impact on content strategy.
While user contributions provide insights into users’ needs, problems they face, and their unique characteristics, not having formal methods to analyze the contributions can lead to several issues. For example, researchers show that it is essential to analyze digital data privacy to build trust through sound user research practices that use data analytics to improve content development and marketing activities (Leonard, 2014; Martin & Murphy, 2017). Ethical research practices lead to proper and transparent privacy policies that in turn provide perceptions about fairness and distributive justice (Petrescu & Krishen, 2018). Privacy is only one issue. Other problems arising due to the lack of strategic methods of audience analysis by analyzing user contributions are un-incentivized contributions or free labor, unauthorized surveillance, and lack of transparency.
This article documents research that helped develop formal methods of analyzing users’ contributions to gain insights about users or audiences that can be used for content related decision-making. Just knowing the methods is not enough; we need to formalize best strategies to incorporate the methods into technical communication research and practice. To do that, I describe my research as a response to the following two main research questions:
- In what ways do users’ interactions reveal their content consumption behavior to inform content strategy?
- How do new methods for user analysis impact the role of technical communicators and the design of information platforms?
The paper starts by providing a background on user research methods and their impact on content strategy. The methods section describes the process of identifying user interaction processes that produce data that can then be used for analysis. The next section elaborates on the findings of interviews conducted with technical communication practitioners to identify methods of user participation that are not visible. The last section elaborates findings that lead to decision-making for content strategy by drawing connections between a user interactions case study and the role of technical communicators, especially information architects, in the process.
Background
Two concepts that are most akin to users’ interactions with content that directly impact content strategy are 1) users’ engagement with content (to access the information they need), and 2) users’ contribution to content development (by producing content). Both of these can be classified as active forms of interaction. When users merely consume content to solve their problems it is known as passive consumption; when they are allowed to make or propose changes to the content, it can be termed as active interaction. An example of passive consumption is when a user reads the documentation topic “Sign up for a Microsoft Copilot Studio trial” on their web browser. However, when they interact with it in a way that produces content, it is called active interaction. Recently, infrastructures have been created in a way that allows users to contribute a great deal to content platforms.
An example of active interaction that leads to content development is as follows: if a user clicks on the edit button (refer to Figure 1) on the documentation portal, they are redirected to the backend which is set up using GitHub. The user can login to the GitHub platform, make edits to the content as required, and submit the change to be considered for publication by the Microsoft documentation team (refer to Figure 2). This can be seen as active interaction. This paper explores methods of active interactions, and how they affect content design. This section will shed light on the further classifications of active interactions, demonstrating how they take place (through example cases) and how they can be used for analyzing users’ information seeking behavior.

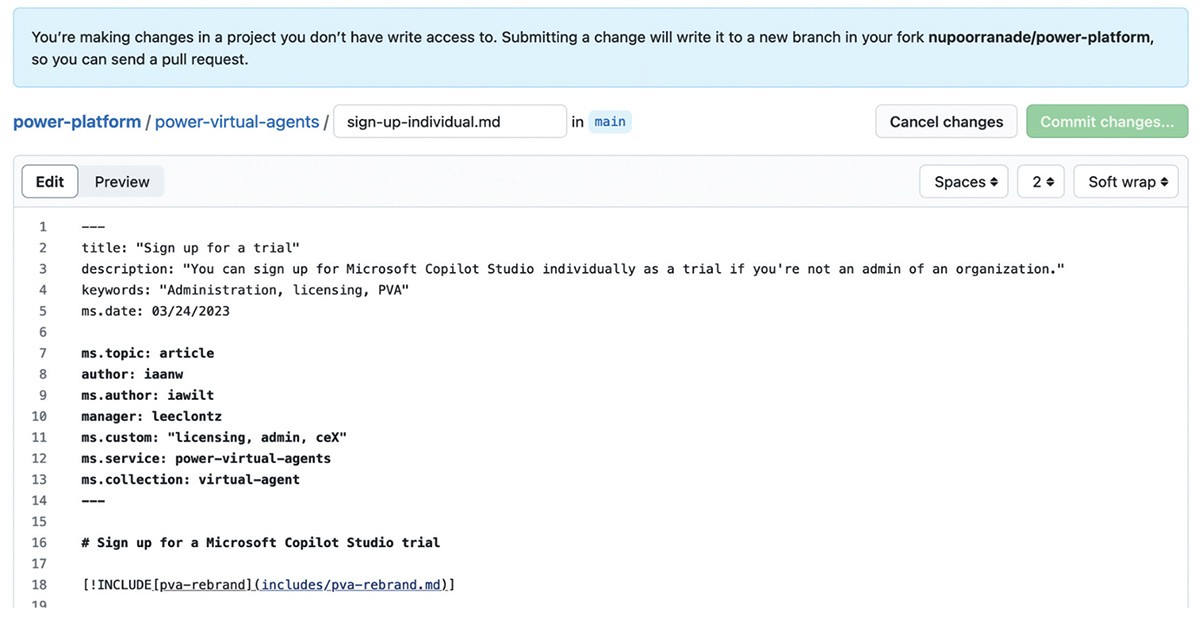
Before diving into the types of active user interactions, we need to define and understand user engagement which is the most common type of active interaction. Engagement is a multifaceted concept manifested in the form of different psychological states including enjoyment, endorsement, and anger, along with behavioral responses such as liking a post or leaving a comment thus generating more content or data that records users’ specific interaction (Kordzadeh & Young, 2022). Action-oriented data can be used as metrics for determining the quality of content; for example, number of likes, comments, and shares are commonly used by practitioners and researchers to measure engagement. In sales and marketing content, popularity of the company, product, or service is based on the number of visitors (hits). Therefore, a high level of engagement is a desirable organizational goal. However, for product documentation, more views could mean that the user experience of the product is not effective which is why the users are having to visit the documentation site more often. Thus, engagement data could be used to question the intuitiveness of the product’s functionality. This phenomenon calls for re-evaluations of the product design itself and its perceived quality (Ranade, 2019).
Another form of active interaction common across web documentation spaces is produsage. I borrow this term from media studies where scholars have used it to describe the technological and technosocial frameworks of user-led content creation (Bruns, 2008). The term was used to highlight the disappearance of the distinction between the roles of “producer” and “consumer” in collaborative spaces. While media scholars discussed Web 2.0 environments such as blogs, Wikipedia, and YouTube, I am specifically interested in the phenomenon as it applies to collaborative documentation platforms like GitHub which allows users to participate in the content production process. Beyond allowing consumers to become producers of content, produsage affords a decentralized system which is different from the typical hierarchical roles. It eliminates the need for “top-down” interventions and conventionally controlled production processes. In this manner, a decentralized process, where users can participate in developing a shared knowledge base allows for every user to document their unique positionality through their contributions, which become part of the documentation platform. When analyzed, these contributions help in expanding user personas beyond those identified by technical communicators through traditional methods such as usability testing.
To discuss users’ active interactions with content, I would also like to discuss the concepts of “implicit and explicit audience participation” also borrowed from media studies. As mentioned earlier, some user interactions do not leave any visible traces of users’ contributions. These can be termed as implicit participation processes. Mirko Tobias Schäfer described the concept of implicit participation as the subtle, conscious engagement of users in online communities which provide more information about their agency (2011). On the other hand, explicit participation is less subtle; it involves active engagement where user data can be revealed instantly. Schäfer (2011) argued that implicit participation is achieved by implementing user activities into user interfaces and back-end design, and the success of popular Web 2.0 and social media applications thrives on such implicit participation. These concepts have contributed to the development of numerous theories of participatory culture. For example, Henry Jenkins and Axel Bruns both focused most prominently on explicit participation (Schäfer, 2011) and formulated theories to understand cultures by analyzing the contributions of community members.
As mentioned earlier, in the technical communication field scholars have explored the ways in which technical communicators can participate in distributed knowledge activities by recording user interactions and making sense of user contributions in knowledge development processes (Breuch, 2018; Frith, 2017; Gallagher, 2020; Swarts, 2007). This work began after the foundational concept audience involved was proposed by Johnson (1997). However, most of the research, like media studies, looks at explicit user contributions. To analyze these explicit contributions, technical communication scholars have studied the ways in which collaborative technical communication spaces operate, where collaborators interact using any means of participation like forum posts, feedback comments, or edits to wiki-based documentation systems. They have also studied the impact of such work on the role of technical communicators, who function as an intermediary between domain experts and users (Ranade, 2021). By understanding desired content gaps between users’ needs and already published content, through these contributions, technical communicators adopt the roles of usability specialists, user advocates, and content designers (Redish, 2010). Redish also cites Mirel’s work to point out that TC researchers have found that well-structured documents may not be useful to users if they are not accessed as expected. Technical communicators can modify content organization and content design so that the content is findable; by editing content, technical communicators are able to address discrepancies across terminology used (that impacts searchability), context creation, and clarity of how the information is interpreted.
This process of conducting user research to design information aligns well with the goals of content strategy. Batova and Andersen (2016) synthesized various definitions of content strategy that are relevant to technical communication work in order to identify their common focus on organizational vision for information and an action plan for achieving it. It is a continuous process which brings together various content development communities (Batova & Andersen, 2016) including users, thus breaking disciplinary silos and biases.
User or audience analysis remains the most important step in content strategy. Analyzing users’ interaction is crucial, but is also under-researched and under-discussed in technical communication scholarship. While citing Weiss’ work, Albers (2004) explains that with most of the challenges of usability and communication already solved (or handled by other teams), technical communicators’ roles need to evolve. A possible direction for evolution is to become content strategists who, along with creating content, also handle user requests by architecting content management systems and documentation databases (Albers, 2004; Andersen, 2014). The back end of product documentation which involves the tools and technologies make it harder for audiences to participate in content production processes. Swarts (2018) argues that such design issues complicate social adaptation and need to be replaced by Mirel’s constructivist documentation approach (1998) in order to include the social, cultural, and technological dynamics of users’ work. Technical communicators’ roles must be elevated for them to content strategists and information architects to be able to mediate between technologies and users. To gauge user problems, they must be allowed to closely monitor users’ contributions. Sharing the genre, context, and technology will motivate users to participate in organizational processes, enabling technical communicators to interact with them more directly. This decentralized approach thereby improves information design. This will help in achieving organizational goals of ensuring that information is made available and accessible to users who are seeking to solve their problems.
Considering implicit user participation allows for a more accurate analysis of users’ needs and problems, as well as the role of information design and information technology (technology used to publish information) that shapes user interactions and content itself (Schäfer, 2011, pp. 51–52). The methods of providing user inputs or feedback raises new questions about the agency of feedback contributors and their role in the technical communication process. Content producers rarely share their positionality with everyone else in the content development network. For example, although anyone can contribute to sites like Wikipedia, or social media sites like Twitter, only that content which gets moderated is made available for public viewing. To understand the roles and positions of stakeholders and users, we need to look at content development processes more closely. Additionally, users’ feedback is more than often related to the problems they are trying to solve and their needs. How can we use feedback from users and their interactions to identify their needs? One way to do that is to treat content moderation as a process that coincides with audience analysis. Once that is done, the audience’s information navigation behavior can be studied to make decisions about content strategy.
So, for this research, it was important to use methods that would look at the back-end design of audience interactions and analyze processes that led to data (or content) creation in some form. To do so, the research was conducted in two stages: first, a mixed-methods approach was used to conduct interviews with practitioners in the technical communication field and to find spaces of user interactions (both implicit and explicit). Then, some of these spaces were studied closely to understand users’ content consumption behavior and the gaps in information design systems. This revealed the roles of users, content designers, technical communication stakeholders, and technology involved in the process of decentralized content development by revealing hidden users on these information platforms.
Methods
This study was developed to identify hidden users by analyzing users’ implicit participation in content development and its impact on content strategy for any information platform. Since previous research has mainly focused on explicit contributions (such as feedback comments, social media posts, etc.), collected data has been more straightforward. To explore implicit participation made by users, this research had to uncover the spaces where such contributions were made by speaking with relevant stakeholders and then analyzing the whole network of relationships that facilitated such user contributions. To do so, I started by first surveying technical communicators in the software documentation industry and then conducting interviews to get more details about processes that collected data from user interactions, and how it was used for user research. In this section, I describe the methodology for my research. I first provide details on the data collection and then the approaches to data analysis, addressing the questions of study credibility and trustworthiness at each stage.
I chose to focus my data collection and research in the computer and software industry for many reasons outlined as follows. Apart from my experience and industry partnerships built over several years in these fields, this choice was dictated by the significant amount of technical communication and user research in the technology industry that this research could contribute to. Audience interactions, especially in online environments, are more prevalent in the software industry. The IT revolution in the late 1980s gave rise to the need to publish product documentation online. Businesses became more globally distributed and teams no longer worked in the same location. The software industry quickly adopted new technology and approaches to allow collaboration among remote teams. Therefore, practices that led to the evolution of content strategy such as structured authoring (Baehr, 2013; Evia et al., 2015; Verhulsdonck et al., 2021), DITA (Evia, 2018; Lam, 2021; O’Neil, 2015; Snow, 2020), content management systems for collaboration and version control (Getto et al., 2019; Getto et al., 2022; Nordheim & Päivärinta, 2006), and agile methodologies for managing product documentation teams, etc., became more prevalent in software industries. Since it was possible to develop, implement, and maintain technological solutions required to complement these approaches completely in-house, software companies became quick adopters as well as leaders in legitimizing these approaches. Additionally, studies such as those by Techwhirl (Document 360) show that over half of the employed technical communicators in the US work in technology-related fields. The U.S. Bureau of Labor Statistics’ employment projections show that a majority of writers from 2019–2029 will be hired by the professional, scientific, and technical services industry. These reasons not only make studying cases from the software industry more important but ensure that results of this research will be applicable to the current and future scene of content strategy practices in the field (Ranade, 2021).
Data Collection
For research studies such as this one, that involve a large, diverse set of users located globally who have access to the same content platforms but may access content in different ways and in multiple languages and play different roles in organizations, it is important to collect data in more than one way. I relied on a combination of data-collection methods that helped me gain a broader perspective of content publishing situations and ensured methodological triangulation at the data-collection stage to avoid researcher bias. The combination of multiple methods of data collection ensured sound methodological design. To gather and study the relevant data, I set up a two-step methodological approach which consisted of observations and interviews.
In the first step, I conducted observations on various product documentation websites to identify spaces of user interactions that led to content generation in software documentation spaces. I studied sites of three different organizations with whom I was employed for three years in total. I also observed websites of other popular documentation websites including Microsoft (docs.microsoft.com), Red Hat (access.redhat.com), IBM (ibm.com/docs), VMWare (docs.vmware.com), and Google (support.google.com/docs/). While working as a technical writer for major companies, I found that many medium scale companies follow the model of popular large scale companies for their information design decisions. I was tasked with conducting a competitor analysis to do the same for one of the three organizations. Therefore, including the popular platforms was crucial.
In the second step, I interviewed practitioners who provided the most current and relevant information about information platforms and the ways in which the implicit contributions were facilitated. Detailed conversations with these practitioners helped me trace the entire process—starting from user interactions that generate content, followed by how technical communicators use that content to analyze users’ needs, and finally how the results of analyses inform decisions about content design. This section will describe these steps in more detail. This study was approved by NC State University’s Institutional Review Board (Protocol Number: #20423, Approved in 2019).
Participant Recruitment Process
For the interviews, I recruited participants from software companies using a targeted selection followed by a chain referral system. First, a list of technical communicators’ names and contact information was created based on my experience of working with them in their respective organizations (during past internships or collaborative projects), or peer-referrals from other employees (except supervisors) who have known their work. I also scanned public profiles (LinkedIn, Twitter, and professional websites) of potential participants who had desirable characteristics based on the stated experience on those platforms. I also publicized the study through a podcast to gain interest from technical communicators in the field. About 60% of the interview participants were recruited using this system. The remaining 40% were recruited through a chain referral system, that is, initial subjects were asked during the interview to identify peers that would be able to make relevant contributions and also be interested in participating in this study. During recruitment, information about the research goals and research process was shared with potential participants over email. If they agreed to the interview request, they were asked to sign a consent form and share their availability for an interview.
With the targeted recruitment, I was able to recruit participants, but the dataset was limited. Because I only reached out to technical communicators in my network, they were from similar geographic regions and had similar demographic characteristics. This would have led to researcher bias. To prevent that, scanning more profiles on LinkedIn helped diversify the dataset (Sullivan & Spilka, 2010; Yin, 2009). The participant dataset included technical communicators with varying experiences (from 1 year to 18 years), who belonged to multiple nationalities, who resided in 3 countries, and who spoke different languages. Most worked with documentation sets written in English, but one person worked with both Chinese and English. Including multiple methods for collecting data helped me achieve methodological triangulation and adjusting the methods based on input from participants allowed me to compensate for the weaknesses of each method.
Interviewing Process
Based on participant availability, interviews were scheduled for one hour each and questions were shared in advance. All interviews took place over Zoom. Interviews were recorded and transcribed before being analyzed for identifying case studies. The interview process for this study was semi-structured (DiCicco-Bloom & Crabtree, 2006; Glaser & Strauss, 2017; Knox & Burkard 2009), that is, the questions lay somewhere between completely structured (or standardized) and completely unstructured. The goal of structured interview questions is to expose all participants to exactly the same interview experience (Fontana & Frey, 2005), so that any differences are assumed to be due to variations among participants rather than to differences in the interview process itself (Fontana & Frey, 2005). Unstructured interviews mostly consist of open-ended questions. Sometimes they start with a single topic-introducing question and the remainder of the interview proceeds as a follow-up and expansion on the interviewee’s answer to the first questions (Kvale, 1996).
A list of 10 structured questions (listed below) was made to ask technical communication practitioners about the practices in which audiences interact implicitly with documentation that results in revealing users’ characteristics that are otherwise hidden from conventional user research practices.
- Do you develop content collaboratively for internal/external documentation?
- Can you describe your role as <professional title/position> at <organization name>?
- Do you have access to users of the project/s you work on either through usability tests, content development processes, analytical software, or any other means?
- How do you solicit contributions from internal and/or external entities?
- Do interactions with users generate content? Is that content used? How do you handle that content? Do users know that they can participate in content development?
- If yes, for content development processes, can you describe the process in detail. How can users participate? How is the content moderated? How many stakeholders are involved?
- What does the publishing process look like from the time they contribute to inclusion or exclusion in released docs?
- What other tools are involved in the process? Are the users/contributors familiar with them?
- How long have you been working with projects that use participation from the community of users? Do you think it has changed the role of business and/or professional communicators?
- How do you manage collaborative projects? (Methodology—agile/kanban/scrum/scaled agile/waterfall).
After learning about their practices, open-ended questions were asked to follow-up and document as many details about the process of content generation and its inclusion into official technical documentation as possible.
Analysis and Findings
I conducted 19 interviews in total. The participant pool consisted of employees who worked for 9 different software companies, who identified as technical communicators, and who played roles such as writers, technical communication managers, content strategists, data analysts, information developers, and information designers for technical communication teams (refer to Figure 3).

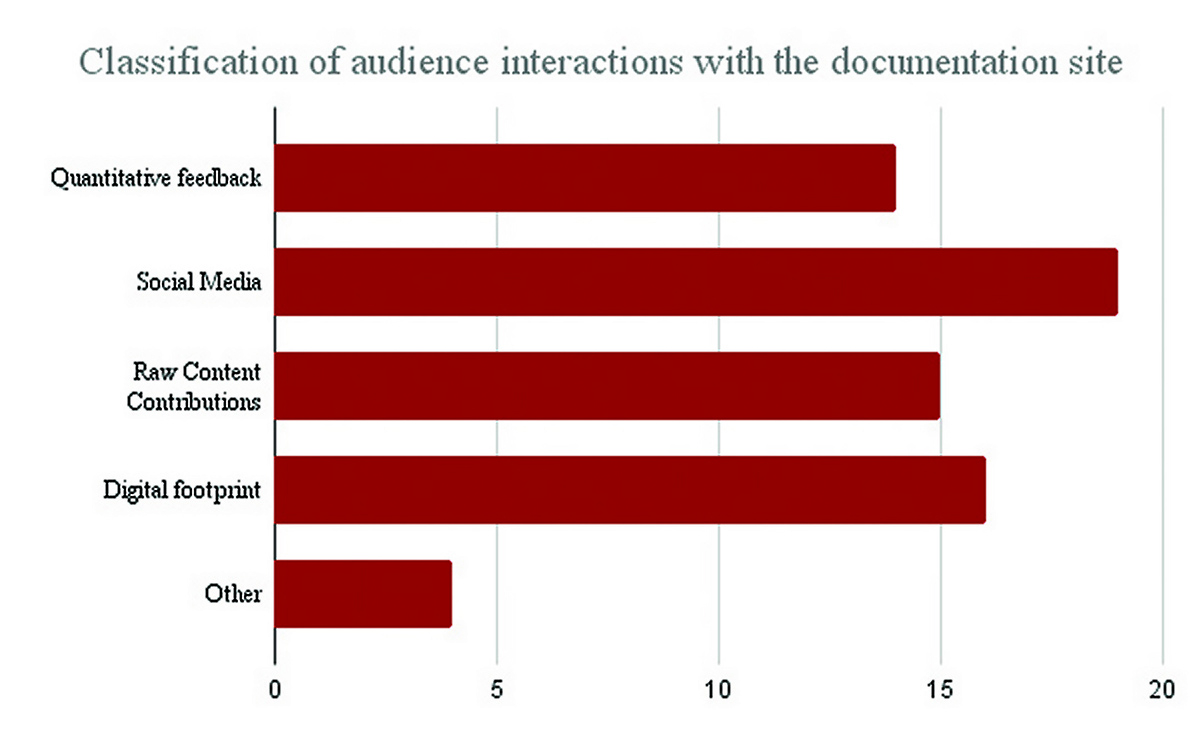
On an average, interviews lasted for approximately 40 minutes (total interview time: 566 minutes). All participants were asked the same set of questions. In cases where data was uniquely relevant to the research, or if responses were not completely clear in terms of providing details of the organizational processes, follow-up questions were asked (35 in total). As mentioned earlier, the chain referral system was used to recruit more participants after the preliminary interviews. After 19 interviews, similar data patterns were observed, so I decided to terminate the interview process. At that point, all interview recordings were saved in a secure location and transcribed to identify viable case studies. A closer analysis of the transcribed interview data revealed several broad categories across which audiences interacted with the documentation platforms (as depicted in Figure 4). They are quantitative feedback (such as a thumbs-up for helpful content, star ratings for a topic, etc.), users’ contributions to the organization’s formal social media platform (such as comments on Facebook, Twitter, or user forums), raw content (such as GitHub contributions), digital footprints (such as data analytics where users’ information navigation behavior like search keywords or navigation pathways that lead to helpful topics, etc. are recorded), and other (those that could not be part of these categories including calls with technical support teams and chatbots).
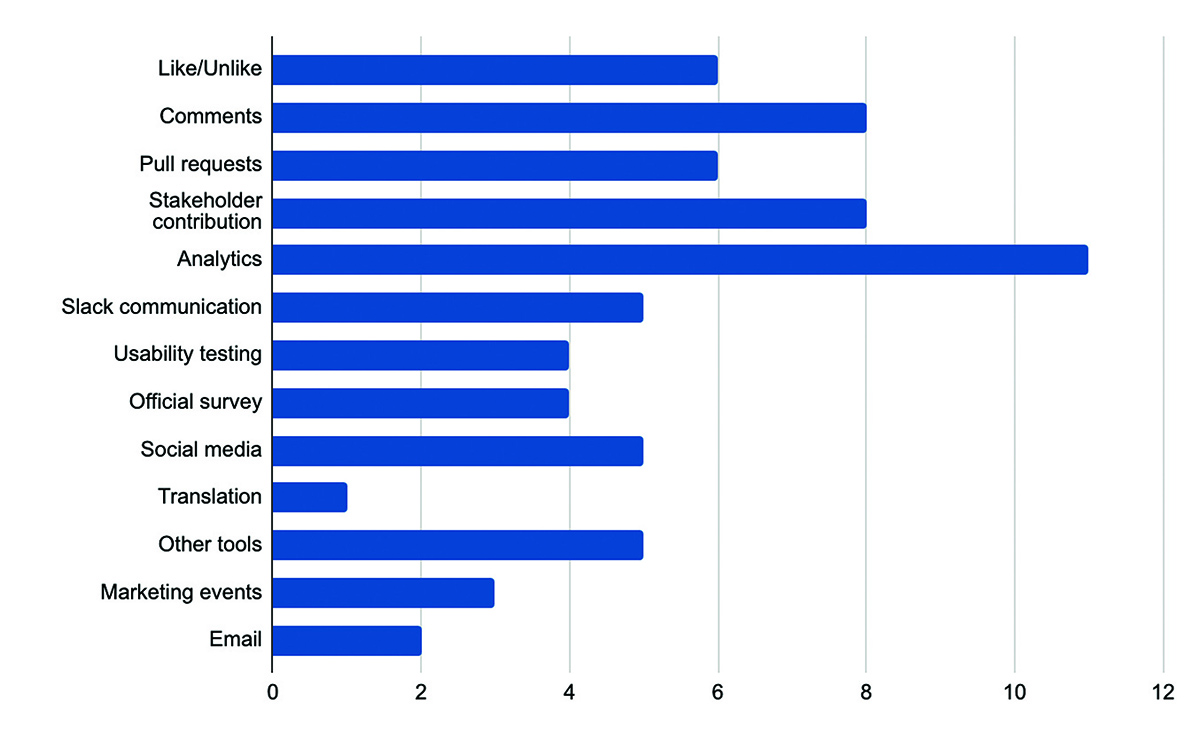
In all, there were 13 practices (refer to Figure 5) in which audiences interacted with documentation platforms and each of those practices could be used to learn about audiences. Among those listed here, qualitative feedback and social media can be counted as explicit interactions. For this research, I only wanted to consider implicit interactions. Therefore, I will discuss those cases from the interviews.
Implicit Interactions of Audiences
In this research, I sought to understand the more implicit user interactions that produce content and their impact on content strategy and in turn on technical communicators’ roles. To identify such invisible audience interactions, I interviewed technical communication practitioners who either designed or utilized content management systems that recorded users’ interactions. The interview questions that gave these practitioners an opportunity to discuss implicit user interactions were:
- Do interactions with users generate content? Is that content used? How do you handle that content? Do users know that they can participate in content development?
- What does the publishing process look like from the time they contribute to inclusion or exclusion in released docs?
- What other tools are involved in the process? Are the users/contributors familiar with them?
The 13 cases mentioned earlier (Figure 5) are methods that practitioners shared to describe their organizational processes of recording user interactions with documentation content. Out of those, 4 approaches can be classified as implicit interactions. They are:
- Pull requests
- Stakeholder contributions (support team)
- Analytics
- Slack communication
Based on the definition provided earlier, implicit interactions are those through which users do not leave any publicly visible traces of their contributions. For example, feedback comments can be viewed publicly, so they are not included in these findings. But pull requests on GitHub can only be viewed by the technical communication team and other internal stakeholders, so they can be included in the data. In this section, I’ll provide more details about these interactions, and discuss how they are facilitated, what information they contribute, what technologies are used for their functioning, and how they affect the organizational content strategy.
Pull requests on GitHub
A pull request (PR) is created by users when they wish to make a change or propose a change to the existing documentation by making the change themselves on the GitHub platform. GitHub is an online platform that provides hosting services using the tool Git (a version control system) which allows efficient management of any information developed collaboratively (for example source code, documentation, etc.) by users. It allows users to create a personalized local copy of information, make changes to it, and, with the permission of the owner of a central repository hosted on GitHub, integrate local changes with the central repository (Ranade & Swarts, 2022). Every permitted, updated version of information is saved in the central repository and locally revised versions are saved in local repositories. These features of the platform allow external collaborators like customers and end-users to contribute to the platform without making visible changes. Fifteen out of 19 participants reported using Git for their documentation management.
Out of the 15, 12 participants used GitHub and 3 used BitBucket. Most participants explained that end-users have to fork the public repository, or create a copy, and make changes to it to convey to the technical communicators that that change needs to be made. From there, the technical communication team mirrors the change on the public facing repository to incorporate that change into the public facing documentation set. When the interviews were conducted (in the summer of 2020), there was no direct process to accept changes by users directly in any of the organizations. Participants also said that most changes were typos. For missing information, such as a specific problem that they were facing, they did not write up content, but “raised it as an Issue” using GitHub.
GitHub Issues allow users to create text-based descriptions of tasks, bugs, changes, and updates in the project and then keep track of them systematically. JIRA is another tool that can be used similarly. However, one participant remarked that most users prefer to use GitHub “because of its simplicity and ease of access compared to JIRA.” Because PRs are generally invisible to the public (unlike documentation), unless users visit the back-end system (like GitHub), user contributions are generally low. Participants from two organizations mentioned that user contributions on GitHub were low until they released a blog post on “How to get involved in the product documentation development process.” After posting about it, users became more active in their contributions and “now communicate directly with one another on GitHub through Issues.”
Analytics
Web analytics is the measurement, collection, analysis, and reporting of web data to understand and optimize web usage. Web analytics tools like Google Analytics (GA) record users’ interactions on online documentation systems in an invisible manner. In most cases, users don’t have access to the data recorded from their interactions. As users access and navigate through the content on documentation websites, web analytics scripts running in the background record users’ activity and collect data points such as which topics the user visited, how much time they spent on a web page, how many users visited a page in an hour, what browser the users used to access the content, which country the user accessed the website from and in which language, and so on. Four participants mentioned that their technical communication team had access to such metrics to help them “spot trends, identify content that audiences spend time viewing, and can make content related decisions based on that.” For example, one participant mentioned that analytics provided them with access to information about “the regions where their users belonged” which helped the technical communication team make decisions about localization. Such data helps ask questions like: Is the content available in the language spoken by most users in the region? Are there any terms that are not translatable and can change interpretation? Have usability tests been conducted to assess the audience in that region? Such questions not only help assess users’ characteristics, but also help tailor the content strategy to specific users’ needs.
Slack communication
Slack is a cloud-based team communication platform developed by Slack Technologies (now owned by Salesforce), that originated as an internal communication tool. It is designed to help teams communicate more efficiently and effectively. Slack allows for communities, groups, or teams to join a “workspace” via a specific URL or invitation sent by a team admin or owner. Slack provides transparency by allowing users to see all the conversations and messages in one place. This makes it easy for team members to catch up on what has been discussed and follow the conversation without having to search through multiple channels or threads. Slack also offers flexibility by allowing users to customize their notifications, so they only receive the information that is relevant to them. This allows members to only follow topics of their interest. Slack offers chat-style features, including persistent chat rooms known as channels, which are organized by topic, as well as private groups and direct messaging functionalities. A workspace can contain both public and private channels, with public channels being accessible to all members of the workspace.
The interviews revealed that at least seven practitioners used Slack to interact with their customers. One way they mentioned was using Slack to “set up channels for various products” where both internal stakeholders (like developers, testers, and technical communicators) and external stakeholders (like customers and end-users) participated in communication activities. The channels were used to broadcast news and important information related to products such as upcoming features and changes to documentation platforms. However, they noticed that these channels were used by customers to “ask questions about documentation, find gaps in documentation, and suggest changes.” Slack channels are used as a dedicated space for communication activities between customers and any other internal stakeholders. It helps them contribute to improving the product and documentation quality by avoiding formalities and “skipping formal task delegation.”
Practitioners from one organization mentioned that their official customer forum was linked to Slack in a way that questions and concerns raised by customers were directly pipelined into Slack conversations. From here they could then be directed to stakeholders responsible for solving the problem. Practitioners mentioned that Slack afforded informal communication, saved time, and improved efficiency. Customers’ questions help technical communicators find issues that are specific to certain customers and the ways in which they use the product. If those are not handled in the documentation, they can take notes and incorporate changes in the next version of the documentation cycle.
Stakeholder contributions
The last category of user implicit interactions is stakeholder contributions. Although only a few participants mentioned these, my study revealed that it was a significant method that recorded user interactions and users’ problems but remained invisible due to disconnect between inter-organizational teams. Two participants mentioned their involvement with the technical support staff that was part of the organization. One of the participants used to be on the support team, and therefore chose to be more involved. The other participant worked with the support team on a different project that led them to discuss documentation problems as well. Support staff routinely interfaced with customers solving their problems on chat tools or over email or phone. They saved records about the calls as documentation which served them if a similar call came in, or if another support staff came across a similar case. However, it was observed that this documentation was not shared directly with technical communicators who were not aware of specific user problems since they did not get to interact directly with these customers.
Two other tools that different stakeholders used across the organization, Pendo and Salesforce, had similar outcomes. As users use the product, Pendo tracks the features used most frequently. Similarly, Salesforce data is recorded and managed by different teams in organizations and consists of content created through users’ actions, such as requesting help from support teams, leaving feedback, and assessing their ability to resolve problems after a support call has been completed. Tools like Pendo and Salesforce contribute significant user knowledge to the organization which gets lost due to the disconnect between different teams. Without communication infrastructures, the use of this data for the purpose of user analysis remains limited and restricted to certain teams. Participants mentioned the need for streamlined processes that would benefit their team and the organization as a whole.
Hidden User
The case studies mentioned in the previous section help clarify the concept of the hidden user. On Git platforms such as GitHub, users can leave comments that, besides themselves, are only visible to administrators who are part of the organization that own the documentation platform. These platforms are used to accept or delete suggestions made by those users, and generally not used for user research due to limited visibility.
Similarly, data analytics access is most commonly provided to marketing and sales teams to improve audience engagement in order to get potential (and existing) customers interested in products and features offered by the organization. Very few participants had access to any data analytics tool. Without the right tool, analytics data—although recorded with every user interaction—remains invisible which restricts technical communicators from being able to study users’ information navigation behavior more closely.
Communication with end users handled through support teams or other stakeholders remains hidden from technical communicators. This happens for many reasons but, primarily organizational silos where business divisions operate independently and thus, individuals are not able to share information across teams.
Content Strategy Implementation
Identifying hidden users has significant benefits—first, organizations are able to study users by using various methods that can help validate results. Second, implicit interactions result in data that’s always already present. It saves costs that are otherwise spent on explicit methods like usability testing. Finally, it provides alternate methods for user research. This study does not suggest substituting these methods for other user research methods, but instead suggests they be used to supplement other forms of research in order to make results more reliable. Such analysis of users and their information seeking (or content navigation) behavior reveals the following implications for content strategy:
- Technical communicators must identify hidden users and find ways to access information about them by breaking silos and building relationships with different stakeholders.
- Technical communicators must develop ethical ways for recording users’ interactions that will help uncover hidden users when other user research methods fail.
Accordingly, I believe that changes can be made to update the content strategy of organizations based on the users’ information received from each of the categories of implicit interactions. I explain this with specific examples of case studies for each category mentioned previously.
Pull requests can be used to find missing content based on users’ requirements. For example, in my past work (Ranade, 2021) I’ve discussed the case study from Microsoft’s documentation website. The user thethales created a pull request to add a small snippet of content—a new procedure to open Performance Monitor (https://github.com/MicrosoftDocs/windowsdriver-docs/pull/2562commits/6be04e06cb2335ae0912025ba52caec0c4eb8241). The PR was assigned to the designated official DOMARS by Ted Hudek, who is another user associated with Microsoft, and handled by DOMARS until it was merged with the original content that appears on the public facing documentation site (https://docs.microsoft.com/en-us/windowshardware/drivers/debugger/determiningwhether-a-leak-exists). Not only was content changed, but the ability of the user to address the need for using the comments feature in the PR creation process provided more information about the user’s specific needs and also a justification for making changes to content. Having such communication infrastructures are important for revising content strategies.
According to the latest work of Hocutt et al. (2024), data analytics can be used to modify the information design and content updates to respond to user needs that may go overlooked by traditional usability testing and audience analysis techniques. For example, user profiles analyzed through web analytics can help technical communicators to identify pathways through which users access information. They can decide whether the existing information architecture supports users’ methods of accessing information. Alignment between existing information architecture and user pathways through the content confirms content design (Hocutt et al., 2024), whereas divergence suggests making changes to the content design by considering additional data points like pages visited, time on page, and session length (Hocutt et al., 2024).
Both stakeholder contributions and the presence of Slack reinforce the need to have direct communication channels with users and to engage in iterative analysis of communication data. For example, support teams can share users’ problems that are related to finding information topics on the documentation website. They can also suggest topics that users frequently need help with. Technical communicators can then classify those topics as “FAQs” or “Relevant Topics” so that they can be found easily. Informal communication through platforms like Slack allow for participation of multiple stakeholders who can help resolve users’ problems but who are separated by organizational or physical boundaries.
Discussion
The method proposed here—understanding users through implicit contributions to inform the content strategy of software documentation platforms—is not a substitute for other methods of user research such as usability testing, qualitative analysis of user inputs, and interviews with stakeholders. It is meant to augment existing methods of content strategy through an in-depth analysis of user participation that otherwise remains unutilized. Following are other considerations of employing this method.
Infrastructure Setup
The role of infrastructure used to connect different components of the process—users, stakeholders, content platforms, technologies—is important and needs to be implemented carefully. The technology needs to be configured such that it supports user interactions and the associations between various components in the communication situation. For example, Slack is an infrastructure that is set up for synchronous communication, and to build a network of users who can help resolve each other’s problems through a shared medium. In such cases, user participation is encouraged and made visible for everyone to participate. Data analytics software can require financial investment. Organizations have to evaluate their return-on-investment (ROI) on such a technology. I argue that web analytics is still affordable compared to usability testing. Usability testing is challenging in terms of finding a good representative sample of participants who have to be incentivized to participate in a study. However, analytics is a service that allows access of data from hundreds or thousands of users spread across the world. While there are ethical considerations to using this data, patterns that are outliers can be used to determine information seeking behavior of minority sets of users, which cannot be done through usability testing methods.
Rules and Regulations
Opening communication channels across all stakeholders requires technical communicators’ intervention through moderation as well as setting up rules and guidelines to prevent contributions that are illegal, inappropriate, harmful, and biased. Some participants mentioned the need for “codified expectations” or an official set of rules and guidelines for user contributions. They include style, structure, and formatting requirements. Rules also reveal the contributor’s authority, gender, tone, and voice. When users are adding content that provides more information about their individual identity, case, needs, and problem, their culture and language is revealed openly. Guidelines must include language that encourages healthy contributions as a decentralized way for the community to solve problems. Opportunities to increase credibility through point systems must be allowed, but not necessarily forced. Point systems are a way to incentivize and encourage users to contribute. But unless it translates into value for the contributor, the incentivization may not be justified.
Formal rules can be published on public viewing platforms like documentation sites. Examples of these are Microsoft’s Contributor Guide (https://learn.microsoft.com/en-us/contribute/) and public Style Guide (https://learn.microsoft.com/en-us/style-guide/welcome/).
Roles of Technical Communicators
In order to analyze users’ implicit interactions, technical communicators need to employ different skills to develop and maintain infrastructures that will record data related to users’ problems and personas. This process must also happen iteratively. The challenging part is to detach from organizational processes outside of those related to content development that technical communicators are conventionally held responsible for. Most practitioners agreed that they play roles beyond content development. Such roles need to be identified, encouraged, and supported in organizations. Some examples of such roles are:
- Content moderators: As more users are contributing to content platforms, technical communicators will have to become content moderators. For example, in the case mentioned earlier, user thethales added a few new lines of content. The designated technical communicator DOMARS not only helped merge the content into the public facing documentation, but before doing that, reviewed it and made sure the information was accurate and suitable for use by other audiences in addition to the user posting it.
- Reviewers: The previous example described a writer’s role in moderating content after reviewing it. Although we can say that the reviewing tasks are not new and writers have always conducted peer reviews within technical communication teams before publishing, reviewing content generated by other stakeholders extends that role even further.
- Content strategists: Technical communicators’ tasks have grown beyond writing to developing information designs that will not only make documentation platforms usable, but also enable users to interact with content more freely. Although only a few participants had these experiences, most participants agreed that their teams are increasingly expected to get involved in usability testing and content strategy operations. By using data to understand users, most writers can make recommendations to improve what gets published.
- Product testers: In the interviews, technical communication practitioners commented that in cases where users such as thethales have reported errors in the content on documentation sites, writers first try to reproduce the errors and then solve it by creating appropriate content. Traditionally, this task was only performed by software testers or the quality assurance team. Due to the direct communication channels between users and writers, writers are able to participate in such processes in order to ensure the accuracy of content.
Conclusion
This study demonstrates that implicit users’ interactions hold significant value for technical communication teams. They help them go beyond traditional usability testing methods to analyze users’ needs and characteristics. They help technical communicators use the findings of that analysis to develop or modify the content strategy of documentation systems. This research can be used to further discussions about the specific methods of deriving data and analyzing it. Some advantages of this method are that it can be used to conduct inclusive design work in order to include diverse audience voices while also building collaborations across the organization. While users can leave feedback, they can also engage in conversations about content updated. This direct communication process allows them to develop relevant solutions for problems that are specific to users’ contexts. Apart from inclusivity, the methodology uses an interdisciplinary approach allowing diverse entities across the organization to participate in audience analysis unlike usability testing or other methods that focus only on a few (in most cases just one) teams. Since all audiences participate (either knowingly on platforms like GitHub, or unknowingly through data analytics), there is a higher likelihood of finding audience needs that are representative of a bigger audience sample.
One limitation of this study is the interview sample. However, after the first 19 interviews, I hit a saturation point in terms of the variety of data that I could derive. Saturation is defined by many as the point at which the data collection process no longer offers any new or relevant data (Dworkin, 2012). There is a variability in expert opinions on what is a minimum number of interviews required for a study like this one. A large body of literature suggests that anywhere from 5 to 50 participants is adequate. Most scholars argue that the concept of saturation is the most important factor to think about when mulling over sample size decisions in qualitative research (Charmaz, 2006; Dworkin, 2012). In this study, I noticed a saturation when the discussions (interviews) with practitioners revealed similar tools and practices used by them to collect user inputs in the documentation development and publication process. The snowball method allowed me to analyze the data soon after collecting it, helping me detect saturation early on in the process. Another limitation is that the results of this study are not generalizable. The study was conducted on software product documentation which is a small part of the technical communication industry. So, the findings are most applicable to technical communicators working in those spaces.
It is true that the method proposed here creates some challenges and concerns for technical communicators. Product documentation platforms are primarily designed for disseminating information to audiences, not for soliciting input. Therefore, technical communicators will have to focus on information design to develop infrastructures that welcome users’ feedback. This raises concerns about incentivization, free labor, and transparency about users’ work for organizations. While these concerns were beyond the scope of this research, it’s important to discuss them before new systems are implemented. Such issues must be analyzed more carefully and audiences must have a choice of participation.
References
Albers, M. J. (2003). Single sourcing and the technical communication career path. Technical Communication, 50, 335–343.
Albers, M. J. (2004). Communication of complex information: User goals and information needs for dynamic web information. Routledge.
Andersen, R. (2014). Rhetorical work in the age of content management: Implications for the field of technical communication. Journal of Business and Technical Communication, 28(2), 115–157.
Baehr, C. (2013). Developing a sustainable content strategy for a technical communication body of knowledge. Technical Communication, 60(4), 293–306.
Barton, M. D., & Heiman, J. R. (2012). Process, product, and potential: The archaeological assessment of collaborative, wiki-based student projects in the technical communication classroom. Technical Communication Quarterly, 21(1), 46–60.
Batova, T., & Andersen, R. (2016). Introduction to the special issue: Content strategy—A unifying vision. IEEE Transactions on Professional Communication, 59(1), 2–6.
Blekanov, I., Bodrunova, S. S., & Akhmetov, A. (2021). Detection of hidden communities in twitter discussions of varying volumes. Future Internet, 13(11), 295.
Breuch, L. A. K. (2018). Involving the audience: A rhetoric perspective on using social media to improve websites. Routledge.
Bruns, A. (2008). Blogs, Wikipedia, Second Life, and beyond: From production to produsage (Vol. 45). Peter Lang.
Burrell, J. (2012). Invisible users: Youth in the internet cafés of urban Ghana. MIT Press.
Carter, L. (2003). The implications of single sourcing on writers and writing. Technical Communication, 50, 317–320.
Charmaz, K. (2006). Constructing grounded theory: A practical guide through qualitative analysis. Sage.
Cooke, A. (2021). Genre uptake as boundary-work: Reasoning about uptake in Wikipedia articles. Journal of Technical Writing and Communication, 51(2), 175–198
Dayton, D. (2006). A hybrid analytical framework to guide studies of innovative IT adoption by work groups. Technical Communication Quarterly, 15, 355–382.
DiCicco‐Bloom, B., & Crabtree, B. F. (2006). The qualitative research interview. Medical Education, 40(4), 314–321.
Doan, S. (2019). Contradictory comments: Feedback in professional communication service courses. IEEE Transactions on Professional Communication, 62(2), 115–129.
Dworkin, S. L. (2012). Sample size policy for qualitative studies using in-depth interviews. Archives of sexual behavior, 41, 1319–1320.
Evia, C. (2018). Creating intelligent content with lightweight DITA. Routledge.
Evia, C., Sharp, M. R., & Pérez-Quiñones, M. A. (2015). Teaching structured authoring and DITA through rhetorical and computational thinking. IEEE Transactions on Professional Communication, 58(3), 328–343.
Fontana, A., & Frey, J. H. (2005). The interview. The Sage handbook of qualitative research, 3, 695–727.
Frith, J. (2017). Big data, technical communication, and the smart city. Journal of Business and Technical Communication, 31(2), 168–187.
Gallagher, J. R. (2020). Update culture and the afterlife of digital writing. University Press of Colorado.
Gallagher, J. R., & Holmes, S. (2019). Empty templates: The ethical habits of empty state pages. Technical Communication Quarterly, 28(3), 271–283.
Gentle, A. (2017). Docs like code. Lulu.com.
Getto, G., Labriola, J. T., & Ruszkiewicz, S. (2022). Content strategy: A how-to guide. Taylor & Francis.
Getto, G., Labriola, J., & Ruszkiewicz, S. (Eds.). (2019). Content strategy in technical communication. Routledge.
Glaser, B., & Strauss, A. (2017). Discovery of grounded theory: Strategies for qualitative research. Routledge.
Hart-Davidson, W. (2009). Content management: Beyond single-sourcing. In R. Spilka (Ed.), Digital literacy for technical communication: 21st century theory and practice (pp. 128–144). Routledge.
Hart-Davidson W., Zachry, M., & Spinuzzi, C. (2012, October). Activity streams: Building context to coordinate writing activity in collaborative teams. In SIGDOC ’12: Proceedings of the 30th Annual ACM International Conference on Design of Communication (pp. 279–287). ACM.
He, W., Wu, H., Yan, G., Akula, V., & Shen, J. (2015). A novel social media competitive analytics framework with sentiment benchmarks. Information & Management, 52(7), 801–812.
Hocutt, D., Ranade, N., Chen, J., & Davis, K. (2024). Data analytics for TPC curriculum. Programmatic Perspectives. (forthcoming)
Johnson, R. R. (1997). Audience involved: Toward a participatory model of writing. Computers and Composition, 14(3), 361–376.
Knox, S., & Burkard, A. W. (2009). Qualitative research interviews. Psychotherapy Research, 19(4–5), 566–575.
Kordzadeh, N., & Young, D. K. (2022). How social media analytics can inform content strategies. Journal of Computer Information Systems, 62(1), 128–140.
Kvale, S. (1996). The 1,000-page question. Qualitative Inquiry, 2(3), 275–284.
Lam, C. (2021). Hashtag #techcomm: An overview of members, networks, and themes from 2016–2019. Technical Communication, 68(2), 5–21.
Lauren, B., & Pigg, S. (2016). Toward multidirectional knowledge flows: Lessons from research and publication practices of technical communication entrepreneurs. Technical Communication, 63(4), 299–313.
Leonard, P. (2014). Customer data analytics: Privacy settings for ‘Big Data’ business. International Data Privacy Law, 4(1), 53–68.
Martin, K. D., & Murphy, P. E. (2017). The role of data privacy in marketing. Journal of the Academy of Marketing Science, 45, 135–155.
McGuire, M., & Kampf, C. (2015, July). Using social media sentiment analysis to understand audiences: A new skill for technical communicators? In 2015 IEEE International Professional Communication Conference (IPCC) (pp. 1–7). IEEE.
Mirel, B. (1998). “Applied constructivism” for user documentation: Alternatives to conventional task orientation. Journal of Business and Technical Communication, 12(1), 7–49.
Nordheim, S., & Päivärinta, T. (2006). Implementing enterprise content management: From evolution through strategy to contradictions out-of-the-box. European Journal of Information Systems, 15, 648–662.
O’Neil, F. (2015, July). Perceptions of content authoring methodologies in technical communication: The perceived benefits of single sourcing. In 2015 IEEE International Professional Communication Conference (IPCC) (pp. 1–8). IEEE.
Petrescu, M., & Krishen, A. S. (2018). Analyzing the analytics: data privacy concerns. Journal of Marketing Analytics, 6, 41–43.
Ranade, N. (2019). The Conundrum of Data Analytics for Audience Analysis. In Proceedings for 2019 CPTSC Annual Conference.
Ranade, N. (2021). Re-contextualizing audiences: New conceptualizations of user interactions in product documentation spaces. North Carolina State University.
Ranade, N., & Swarts, J. (2022). Infrastructural support of users’ mediated potential. Communication Design Quarterly Review, 10(2), 10–21.
Redish, J. (2010). Technical communication and usability: Intertwined strands and mutual influences. IEEE Transactions on Professional Communication, 53(3), 191–201.
Rude, C. (2009). Mapping the research questions in technical communication. Journal of Business and Technical Communication, 23, 174–215. https://doi.org/10.1177/1050651908329562
Salvo, M. (2004). Rhetorical action in professional space: Information architecture as critical practice. Journal of Business and Technical Communication, 18, 39–66.
Schäfer, M. T. (2011). Bastard culture. How user participation transforms cultural production, 6.
Snow, H. M. (2020). A survey of current best practices for technical communication practitioners dealing with legacy content. University of Minnesota Digital Conservancy.
Spears, R., & Lea, M. (1994). Panacea or panopticon? The hidden power in computer-mediated communication. Communication Research, 21(4), 427–459.
Spinuzzi, C. (2012). Working alone together: Coworking as emergent collaborative activity. Journal of Business and Technical Communication, 26(4), 399–441.
Sullivan P. A., & Spilka R. (2010). Qualitative research in technical communication: Issue of value, identity, and use. In J. Conklin, & G. F. Hayhoe (Eds.), Qualitative research in technical communication (pp. 1–24). New York, NY: Routledge.
Swarts J. (2010). Recycled writing: Assembling actor networks from reusable content. Journal of Business and Technical Communication, 24, 127–163.
Swarts J. (2011). Technological literacy as network building. Technical Communication Quarterly, 20, 274–302.
Swarts, J. (2007). Mobility and composition: The architecture of coherence in non-places. Technical Communication Quarterly, 16(3), 279–309.
Swarts, J. (2015). Help is in the helping: An evaluation of help documentation in a networked age. Technical Communication Quarterly, 24(2), 164–187.
Swarts, J. (2018). Wicked, incomplete, and uncertain: User support in the wild and the role of technical communication. University Press of Colorado.
Toffler, A. (1970). Future shock, 1970. Sydney. Pan.
Turns, J., & Wagner, T. S. (2004). Characterizing audience for informational web site design. Technical Communication, 51(1), 68–85.
Verhulsdonck, G., Howard, T., & Tham, J. (2021). Investigating the impact of design thinking, content strategy, and artificial intelligence: A “streams” approach for technical communication and user experience. Journal of Technical Writing and Communication, 51(4), 468–492.
Westlund, O., & Lewis, S. C. (2014). Agents of media innovations: Actors, actants, and audiences. The Journal of Media Innovations, 1(2), 10–35.
Whittemore S. (2008). Metadata and memory: Lessons from the canon of memoria for the design of content management systems. Technical Communication Quarterly, 17, 77–98.
Wieringa, J., Kannan, P. K., Ma, X., Reutterer, T., Risselada, H., & Skiera, B. (2021). Data analytics in a privacy-concerned world. Journal of Business Research, 122, 915–925.
Yin R. (2009). Case study research: Design and methods (4th ed.). Sage.
Yoshida, T. (2013). Toward finding hidden communities based on user profile. Journal of Intelligent Information Systems, 40, 189–209.
About the Author
Dr. Nupoor Ranade is an Assistant Professor of English at Carnegie Mellon University. Her research addresses knowledge gaps in the fields of technical communication practice and pedagogy, and focuses on professional writing and editing, inclusive design, and ethics of AI. Through her teaching, Nupoor tries to build a bridge between academia and industry and help students develop professional networks while they also contribute to the community that they are part of. Her research has won multiple awards and is published in journals including, but not limited to, Technical Communication, AI & Society, Communication Design Quarterly, and IEEE Transactions on Professional Communication.
