By Gustav Verhulsdonck, Jennifer Weible, Danielle Mollie Stambler, Tharon Howard, and Jason Tham
Abstract
Purpose: As technical and professional communicators (TPCs) use AI to develop content, inaccuracies due to AI limitations are introduced; it is vital TPCs evaluate AI-generated content to improve accuracy and human-centeredness. In this article, we present a human-in-the-loop AI content heuristic (HEAT: Human experience, Expertise, Accuracy, and Trust) as a rating mechanism.
Method: This exploratory case study evaluated the quality of content generated by ChatGPT from the perspective of beginner TPC students. We used multiple prompting strategies asking ChatGPT to create documentation on personas using two Darwin Information Type Architecture (DITA) information types namely, concept topics and task instructions, and we evaluated the results with HEAT.
Results: HEAT had good intraclass correlation coefficient (ICC) reliability (.743 pilot; .825 for scenarios) indicating its fitness as a heuristic for evaluating generative AI output. The findings indicate that ChatGPT was generally good at writing concept topics; however, it performed less well creating step-by-step task instructions. Expert TPC input helped develop a better prompt for improved output. We also found that tokenization in ChatGPT (the way it breaks up text) has a large role in terms of non-compliance with format specifications.
Conclusion: There is a need for TPCs to (1) develop new models for AI-assisted content creation, (2) recognize the impact of different prompting strategies on developing specific structured authoring units such as concept and task topics, and (3) be aware of the limitations of AI such as ChatGPT. Human-in-the-loop quality check mechanisms, such as HEAT, can help validate and modify AI-generated content to better serve end users.
Keywords: Generative Artificial Intelligence, Content Development, Case Study, UX
Practitioner’s Takeaway:
- TPCs can use the HEAT model to check AI-assisted content quality.
- Different prompting strategies and roles for AI in generating output may foster new co-creation models.
- Expert intervention is necessary: ChatGPT performed well on specific structured authoring information units for developing conceptual information (e.g., concept topics) but performed poorly on writing step-by-step instructions (e.g., task topics).
- TPCs are still needed to write quality prompts and assess AI output. We found that AI generated better output when prompts were written by an expert.
Introduction
In the case of artificial intelligence (AI), the saying things move so fast in the digital world that one internet year is equivalent to three months has merit. In May, the 2023 State of User Research Report stated that 20% of researchers reported using AI in their work (Balboni et al., 2023, n.p.). Three months later, a follow-up survey of 1,093 researchers showed that number had jumped to 77.1%. In a March 2024 UX Writing Hub workshop, content designer/UX writer Andrew Stein noted how AI asks technical writers to show up differently in workplaces and suggested adopting the title AI Content Lead. Additionally, Stein stated that the proliferation of AI content development practices caused the freelance platform Upwork to drastically decrease requests for freelance writers. Although growth in the number of technical and professional communicators (TPCs) using AI in the workplace is high, there is considerable anecdotal evidence that users’ confidence in AI-generated content is low. Ethical concerns abound about Generative AI (genAI) Large Language Models’ (LLMs) lack of consistency and sometimes fabricated answers (so-called AI hallucinations).
The work of TPCs is 100% impacted if companies outsource work to only a few content developers who oversee content generated by AI for end users (Eloundou et al., 2023). If AI’s speed is equated with efficiency, companies run the risk of neglecting content quality issues related to human experience, writer expertise, information accuracy, and human trust. For example, poorly developed chatbots have caused major legal and financial headaches for Air Canada and Google by fabricating non-existent customer policies or inaccurate information (Milmo & Wearden, 2023; Price, 2022). Hence, TPCs must advocate for human input as companies try to automate AI content development.
Since AI can generate and analyze text, recommend ideas, identify user sentiments, develop interface prototypes, and create user personas from scratch, we can expect the integration of AI in various stages of content creation. Given fast-moving industry developments in AI, it is critical we assess how it can help develop content at various stages (see Duin & Pedersen, 2021, 2023; Tham et al., 2022; Verhulsdonck et al., 2021). Research on the role of content strategy has already signaled changes in TPC workflows through reduced time spent on brainstorming and drafting, freeing up more time for creative, higher-level endeavors (Bridgeford, 2020; Getto et al., 2019, 2023; Nielsen, 2023; Noy & Zhang, 2023). According to Graham (2023), instructors must advocate for post-process writing practices and help students learn “prompt-engineering, output curation, fact-checking, and revision” while writing with AI in a recursive manner (p. 166). Expanding on this, Knowles (2024) recommended that we avoid “offloading the entire rhetorical load to AI” and instead rely on human writers with augmentation by AI (p. 3). Hence, whether content works for users depends on developing robust AI-TPC content co-creation practices. Such practices require TPCs to understand how to incorporate human experience and writer content expertise, as well as assure AI content is accurate and can be trusted by users. Further, as TPCs are attuned to ethical issues, bias, user advocacy, and social justice (Jones, 2016; Rose & Walton, 2018), it is vital for TPCs to check the work of genAI to better address diverse end users.
Because TPCs may not be aware of genAI limits, it is paramount that our field establishes appropriate reliance on genAI and develops workable models for AI content co-creation. In this article, we present a human-in-the-loop heuristic, HEAT (Human experience, Expertise, Accuracy, and Trust), for rating genAI output quality, which asks TPCs to check how genAI content maps onto the physical world of the user (Human experience), to use mental models and schemas to help the user (Expertise), and to confirm the output is accurate (Accuracy) and trustworthy (Trust).
In what follows, we outline literature on LLMs and their limitations, highlighting the need for trustworthy and ethical AI. We describe a theoretical framework for checking AI output that acknowledges these shortcomings, followed by a description of our methods, prompt design, use of ChatGPT, and use of the HEAT heuristic. In our Results and Discussion section, we demonstrate how ChatGPT was better at developing concept information than writing task instructions. We conclude with takeaways for TPCs on using genAI for content co-creation.
Literature Review
While many companies dream of automating their writing workflow through AI (Barker, 2021), it remains a far-off scenario. AI’s speed cannot replace a human writer’s attunement to human experience or expertise if the AI does not recognize the physical context of its content or whether its output is hallucinated. However, we believe AI can play a collaborative role with TPCs through human-machine teaming (Duin & Pedersen, 2021, 2023). According to content strategist Robert Rose, content generation “is the least interesting thing that ChatGPT and other generative AI tools do” (Fisher, 2023, n.p.). For example, genAI can engage in role-playing by taking on a specific role in content development (“acting as a UX researcher, identify top ten pain points in the user comments provided”) or persona (“acting in the role of persona Susan, analyze this interface for pains and gains”) in quickly analyzing and generating input. GenAI can also function as a brainstorming partner, content re-organizer/extractor, copy rejuvenator, and sentiment/data analyst (Fisher, 2023). Therefore, it is crucial to recognize how genAI will alter existing TPC content development processes.
It is vital to address the emergent properties of LLMs and to understand that while we were writing this article, newer, faster, and more improved versions of AI were emerging. Our goal here is to inform a critical perspective for TPCs. While LLMs have the capacity for autopoiesis and emergent behavior—e.g., continuous self-organizing as they learn from users—LLMs cannot adequately address all user contexts. For example, a review of common ChatGPT errors mentions its lack of addressing real-world physical dimensions, errors in math, and difficulty dealing with ethics, human bias, and human reasoning (Borji, 2023).
Current genAI is not foolproof as LLMs fabricate convincing sounding but incorrect content (so-called hallucinations). GenAI such as ChatGPT are trained on Common Crawl—a dataset of roughly 570 gigabytes as of this writing, consisting of Wikipedia data, outbound links from Reddit, and an unknown number of published books (Bender et al., 2021). Therefore, AI researchers warn that LLMs are problematic “stochastic parrots” that reinforce harmful stereotypes, have biases in content, and create potential for misuse (Bender et al., 2021, p. 616). For example, poor AI model training on bank loans based only on upper- and middle-class customer data may erroneously deny low-income households. As AI theorist Luciano Floridi (2023) noted, LLMs liberate “agency from intelligence” where AI acts like it has understood you but does not understand what it has generated (p. 16). Combined with LLM issues of copyright violations; the human cost of contractors labeling harmful content in Kenya for less than $2 per hour; algorithmic poisoning impacting crucial financial, medical, or other important human decisions; it is clear that automating all content is not the answer (Floridi, 2023). Hence, a wicked problem exists: genAI LLMs can generate convincing output that is biased, incorrect, or not rooted in reality. These issues are crucial for TPCs to identify and may negatively affect assessments of genAI content automation.
While LLMs display emergent behavior, researchers are mixed in their assessment on how LLMs may overcome the above issues. Increasing the amount of training data for an LLM creates more hallucinations because of the larger dataset (Lin et al., 2021). Also, model deterioration of LLMs may occur if future LLMs are trained on hallucinated, factually incorrect AI-generated content together with human-generated content (Shumailov et al., 2023). Since LLMs use machine learning techniques to reward better answers, an intractable issue exists as algorithmic reinforcement relies on the quality of prompts provided by human users. Hence, researchers propose instruction tuning by feeding LLM supervised learning tasks that help train AI to create better output (Christiano et al., 2017; Touvron et al., 2023; Wei et al., 2021). Chain-of-thought prompting—where a prompt writer makes explicit their reasoning, provides an example of desired output, and gives crucial context for reasoning in the prompt—can also increase the effectiveness of LLMs in producing higher quality desired output (Wang et al., 2022; Wei et al., 2022). Meanwhile, complete automation of content creation is not yet feasible; quality content development requires understanding the context, structure, and user needs, as well as writing a strong prompt and carefully evaluating output—skills that TPCs bring to content development processes.
Human-in-the-Loop: Need for Human Judgment
While automation of content may be seen as a means of better efficiency, it is vital that TPCs recognize that “instead of thinking of automation as the removal of human involvement from a task, [it is actually] … the selective inclusion of human participation” (Wang, 2019, n.p.). We argue that a human-in-the-loop perspective includes incorporating human input and judgment to assess and modify AI-generated content toward nuance and quality.
As there is a perceived bias, lack of transparency, and accountability in AI training models, calls for more human-in-the-loop, ethical standards abound (Brundage et al., 2020; Noble, 2018; World Economic Forum, 2022). Researchers call for more “human-centered,” “ethical,” “explainable,” “responsible” AI based on equity and inclusion of diverse human perspectives (Verhulsdonck et al., 2021; World Economic Forum, 2022). Given the nature of TPC work in inferring the total experiences (emotions, pains, and gains) of users and their physical surroundings in a dynamic context, it is crucial to build in human-in-the-loop mechanisms to check AI content for human-centeredness and accuracy to safeguard users.
Theoretical Framework: Addressing How We Judge AI Output
Important moments in human creativity are at the beginning (generating ideas) and ending (evaluating where something works or is desirable to implement) of a process. With AI, that means writing strong prompts and evaluating output. However, human creativity is not just about idea generation (something genAI can do). Humans also exercise judgment: applying ideas to new contexts, identifying problems worthy of problem-solving, and evaluating the effectiveness of a particular course of action (Csikszentmihalyi, 1988; Vinchon et al., 2023). Such creative endeavors are central to many TPC activities in addressing end users and their physical contexts and reinforce that AI content still needs to be evaluated and refined to better work for human ends.
When working with AI, human judgment is impacted by two human factors: AI literacy and cognitive biases. Passi and Vorvoreanu (2021) identified that differences in people’s AI literacy—their level of expertise, task familiarity, and prior exposure to AI—influences whether they see AI output as trustworthy. Additionally, cognitive biases such as confirmation or automation bias may lead people to wrongly deem AI output correct if it confirms their initial idea or is automated (Passi & Vorvoreanu, 2021). Hence, researchers warn people not to over-rely on AI output without incorporating their own critical judgment. For example, a study of medical professionals found that both low- and high-expertise groups developed high dependency on AI recommendation systems (Gaube et al., 2021). Other AI studies also show that perceived mismatch between expected answer and generated AI output may lead people to change their answer to align with AI (Kim et al., 2021; Springer et al., 2017). In response, researchers in AI trust and accountability emphasize the critical need for contextualizing the quality of AI output to support better human judgments and reduce overreliance on AI (Springer & Whittaker, 2020).
HEAT Model
It is important for TPCs to understand what genAI can and cannot effectively do. Given that LLMs cannot always overtly address specific physical human experiences, it is vital TPCs check for this. Likewise, since LLMs do not always incorporate human nuance, TPCs need to bring their writing expertise. Further, due to LLMs hallucinating incorrect content or generating biased output, it is vital TPCs ensure accuracy and foster trust for users. Our HEAT model is based on developing such human-in-the-loop perspectives, asking TPCs to use four elements—human experience, expertise, accuracy, and trust—to evaluate genAI output (refer to Table 1).
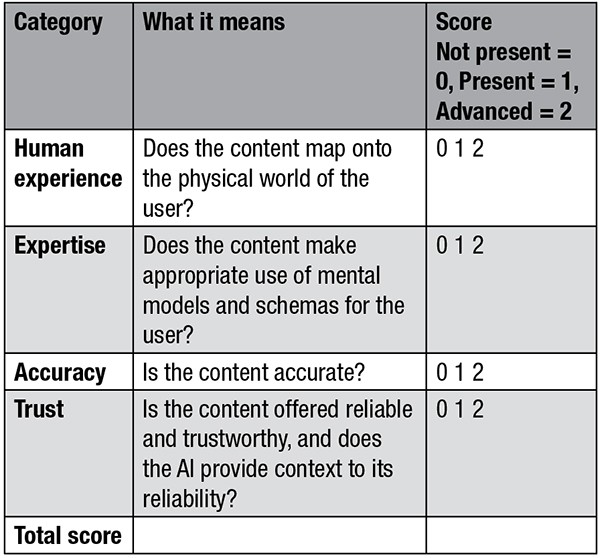
We suggest the HEAT model as a mnemonic evaluative heuristic for TPCs to quickly assess genAI output. While there are other criteria (e.g., is the content biased, is it harmful to specific users), the HEAT heuristic serves as a scoring mechanism to assess genAI output and reminds TPCs that using their human perspective to check and modify genAI content better addresses users and their contexts.
Methodology
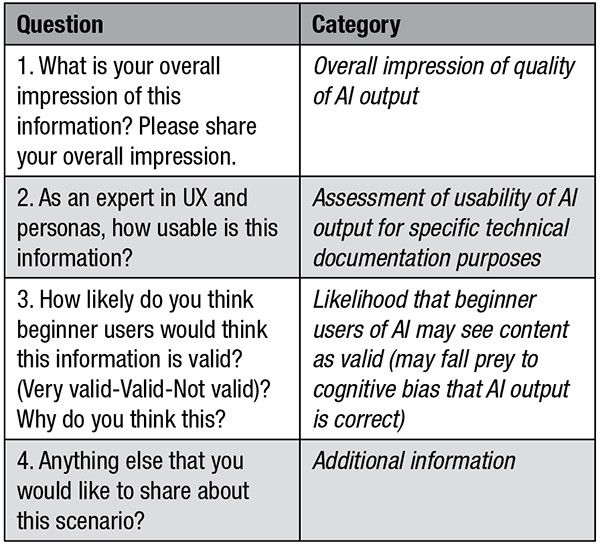
A goal of this study was to validate the HEAT heuristic as a scoring mechanism for TPCs to evaluate AI-generated content. We used the HEAT heuristic along with open-ended questions (see Table 2) to evaluate the quality of AI-generated content output from a common open-access LLM (ChatGPT 3.5) in response to our prompts.
Overall, we wanted to investigate ChatGPT’s performance in two distinct types of DITA content categories, writing conceptual information and step-by-step task instructions. We operationalized these categories as follows:
- “Concept topics present essential conceptual or descriptive information so the reader can understand the background and context of a subject.
- Task topics provide procedural information on how to do something” (Clark, 2017, n.p.; also refer to Evia, 2018).
We explicitly operationalized our scoring based on the context of beginner students and tallied the results of our evaluation. This meant we evaluated content from the perspective of beginner students working to learn how to interact with LLMs such as ChatGPT with one-time prompt strategies and exhibiting more shallow evaluation of content versus our more expert understanding. Our assumption here was first- or second-year college students might see information as more valid—e.g., trustworthy, or credible—if it appeared to answer their question or incorporated terminology from the prompt.
Hence, we used the HEAT model to quickly score whether genAI content was appropriate in the categories of human experience, expertise, accuracy, and trust. After, we answered open-ended questions (refer to Table 2) and reflected on whether we thought generated content (1) worked, (2) was usable, (3) was valid, and (4) we noted our overall impression from the perspective of our beginner students.
Our aim in this study was to get answers to the following research questions:
- How can the HEAT model be used to evaluate the quality of genAI output? Is the model workable in terms of assessing the quality of output?
- What level of quality output is created using generative AI (ChatGPT3.5) when creating concept versus task information when using different prompting strategies?
We ran a pilot study followed by three more advanced scenarios. The pilot study utilized simple prompts by asking ChatGPT “what is a persona,” “what is a persona in user experience design,” and “how do I create a persona in UX”—e.g., DITA concept information on personas and task information on how to create a persona. We found ChatGPT performed relatively well on creating conceptual information about personas; whereas it performed somewhat poorly on the task information—how to create a persona. The simple prompts allowed ChatGPT to do what it was asked (e.g., writing good conceptual content on personas); however, step-by-step task output was too broad to implement. Nevertheless, in both cases, ChatGPT performed well on average.
Our overarching goal was to experiment with different prompting strategies to create more advanced AI development scenarios. We used the following advanced scenario prompts to test the ability of ChatGPT to create content with different levels of involvement of AI and TPC:
- Scenario 1: Chain-of-thought prompt with explicit mention of the difference between DITA concepts and task formats. The AI was primed to understand the difference in formats and write in these formats. This prompt was used to explore ChatGPT’s understanding of DITA and ability to write in either concept or task format.
- Scenario 2: Self-refining AI prompt (see Louw, 2023) where AI was asked to refine our prompt by asking questions to create an improved prompt that met our expectations (AI-in-the-loop). This prompt examined whether ChatGPT understood what we were asking, could ask questions and refine a prompt based on the TPC’s answers, and could produce a more robust concept and task output.
- Scenario 3: Expert chain-of-thought prompt written by one of the authors as a TPC expert for concept and task. We used this prompt to make explicit our chain of reasoning and provide format expectations for output to see if TPC input would create better quality output.
Our aim for the scenarios was to explicitly incorporate human judgment in the process of both prompting and evaluating generated content. Scenarios 1 and 3 involved a higher level of TPC involvement in writing the prompt, whereas scenario 2 modeled a collaborative scenario where ChatGPT helped refine the prompt for better output by asking a number of questions before execution.
Participants
The participants in this study are the 5 authors. All are considered experts in their field.
Data Generation
We conducted this study December 2023–January 2024 with the understanding that LLMs are continuously learning and developing. We used the free version of ChatGPT 3.5 to mimic everyday student uses of genAI in creating content. One author generated the prompts and outputs and selected the most salient one, then all authors rated the chosen outputs.
Scoring Process
The prompt and outputs were shared with raters with an indication of whether the prompt and content were for a concept or a task topic. The five authors independently read and rated each of the AI-generated outputs using the HEAT heuristic (refer to Table 1) in two rounds: Pilot and Scenarios. Scores were totaled for each output as well as averages calculated for each category in the HEAT heuristic. Each rater answered additional open-ended questions (refer to Table 2) to better gauge the quality of AI output. The open-ended questions were analyzed thematically using qualitative analysis techniques (Creswell & Creswell, 2018). The authors met to discuss ratings and open-ended questions and to ensure fidelity of scoring. This process gave us a baseline to understand the quality overall (total score) and how we evaluated the AI output (through the open-ended questions).
Avoiding Bias and Justification for Methods
During creation of the corpus, answers were generated three times; the most salient example was selected to evaluate best quality output rather than random selection or first output generated. During analysis, the genAI output was evaluated independently before discussion to eliminate bias. We debriefed using reflective commenting to evaluate the quality of ChatGPT output.
Limitations
We note our scenarios represent typical (but not exhaustive) scenarios of content development geared toward co-creation of content by AI. We aim to demonstrate the necessity of incorporating human judgment in generating content with AI. We acknowledge genAI tools are developing in sophistication and may improve in specific writing tasks.
Results and Discussion
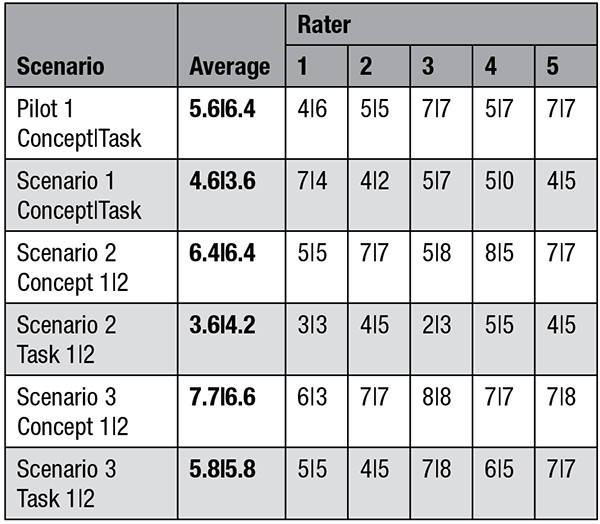
We scored all our pilot and three scenarios with the HEAT heuristic as follows (See Table 3):
Reliability of the HEAT Model
We utilized the intraclass correlation coefficient (ICC) to assess the reliability of scoring using the HEAT heuristic; ICC integrates both the degree of correlation and agreement between measurements when determining reliability (Koo & Li, 2016). A blind review process was used; five experts scored each response independently (12 total; 2 scores of the pilot, 10 scores of the scenarios). The ICC was calculated with SPSS using a two-way mixed model, average measurement, and consistency. For the pilot, reliability was found to be good between eight measurements. The average measure ICC was .743 with a 95% confidence interval from .155 to .970, F(4,28) = 3.889, p = .012. The raters discussed the application of the HEAT heuristic and rated an additional ten responses independently to further validate the model. Reliability was found to be good between 48 measurements with the average measure ICC being .825 with a 95% confidence interval from .501 to .979, F(4, 188) = 5.724, p < .001. Thus, we posit that the HEAT model has good reliability when used as a heuristic for evaluating AI output.
Scenario 1: Chain-Of-Thought Prompt
The goal of chain-of-thought prompts is to make explicit one’s own reasoning to ChatGPT for better output. For our prompt, we drew upon OpenAI’s guidelines to reveal our chain-of-thought with specific format requests. We asked ChatGPT to roleplay (act as a technical communicator) and specified required format (user documentation and DITA concept or task content) and delimiter (4–5 paragraphs). As part of the delimiters, we primed ChatGPT with specific input on the DITA concept and task formats and asked if it understood the different categories for DITA, which it said it understood. For both scenarios, we used this input as a delimiter by using triple quotation marks and confirmation of understanding to identify the beginning and end of specific information units (refer to Figure 1).

Scenario 1 Prompt for Concept: “Acting as a technical communicator that uses Concept topic format, please describe what a user persona is in the field of UX. Write in 4–5 paragraphs. Provide full description that is ready-made and can be used in user documentation.”
Scenario 1 Prompt for Task: “Using IBM’s Task topic format in DITA and acting as a technical communicator, please describe what a user persona is in the field of UX. Write in 4–5 paragraphs. Provide full description that is ready-made and can be used in user documentation.”
The output of these two prompts were unexpected given the precision of the prompt and the following of OpenAI’s guidelines for better output. Of note, we checked before whether ChatGPT knew about DITA, which it confirmed by quoting us back the format. However, in its output, we saw an awkward synthesis that indicated it did not understand the request and hallucinated its response. For TPCs, this is an important finding—ChatGPT has not (yet) mastered DITA concept and task format writing.
Second, ChatGPT was unable to distinguish format requests from assigned topics. ChatGPT’s concept output featured multiple introductory sentences like “Adopting IBM’s Concept Topic format,” or “Within the Concept Topic format” which was an undesired output; we asked it to adopt that format, not write about it. Likewise, it concluded, “In summary, within the conceptual paradigm of UX design, using personas crafted by the Concept Topic format serve as conceptual guide,” showing ChatGPT tried forcefully to connect these ideas.
Hence, for the concept, ChatGPT tried to connect the concept topic of personas to DITA, and its output suffered as a result. One researcher noted, “I was not expecting the writing […] to become so atrocious […] How many times can you use the word ‘concept’ in this response? Too many!” and a second, “There was a lot of wordiness and filler added (how many times can it say conceptual?) that made it sound less knowledgeable.”
For the task, ChatGPT did not use hierarchical ordering of one step/action following another from structured authoring. Instead, ChatGPT returned an agenda-style sentence: “Leveraging IBM’s Task Topic format in DITA, we can delve into the structured creation of a user persona, an indispensable tool for human-centered design.” However, while it gave “Defining user personas,” “components of user personas,” “informing design decisions,” and “facilitating collaboration” as headers above paragraphs, the content it provided erroneously related personas to DITA generally.
Overall, in both prompt outputs ChatGPT failed to write in the specific manner requested and instead treated our request for a specific technical writing format as a topic. The failure to write in our requested formats is interesting. In future prompts, we could implement more explicit chain-of-thought prompting, e.g., specify we want a numbered list for tasks, and only conceptual information for concepts.
Scenario 2: Self-Refining Ai Prompt
In the second scenario, we leveraged a self-refining AI prompt (Louw, 2024), which features specific instructions for ChatGPT to “function as a specialized AI prompt engineer,” interrogating the user following a “structured process for iterations of continual improvement” (n.p.). This scenario instructed ChatGPT to (1) make an initial inquiry on the subject and objective of the prompt; (2) based on input from the user, create an enhanced prompt; (3) ask clarification questions of the user to improve the prompt for both AI and specific user needs; and (4) to repeat this cycle until all its prompt specification questions had been answered for the revised prompt.
Through self-refining prompts, ChatGPT becomes an active interlocutor in writing a prompt by asking the technical communicator multiple questions based on its internal modeling and understanding. Whereas chain-of-thought prompting asks TPCs to explicitly model the format and structure before ChatGPT carries out the task, the self-refining prompt reverses that process.
This type of interactive AI prompting is interesting because ChatGPT shares its modeling and understanding. The back-and-forth with ChatGPT made it recommend a versatile prototyping tool with general accessibility and popularity (it recommended Adobe XD, Figma, and Sketch for this) and using Unsplash.com (an open-license image website) for persona development, among other improvements. Hence, we found the self-refining AI prompt challenged us to write a stronger prompt through collaboration.
That said, our experience was mixed. When we tried to create a task topic, ChatGPT completed its questioning in only 6 iterations. On a concept topic, it asked us 21 follow-up questions with no end in sight. To create a workable prompt, we intervened and retried the process, giving shorter answers. Hence, we stopped our final concept prompt after 7 iterations, which we felt was sufficient:
Scenario 2 Prompt for Concept: “Compose a formal paragraph (less than 250 words) providing a general overview of the concept of persona in user experience design. Construct a concise structure with a topic sentence, a main section explaining the role of personas in understanding user needs and behavior, and a conclusion highlighting their significance in creating user-centric interfaces. Additionally, include a conceptual example focusing on the creation process, utilizing a simple hypothetical username to illustrate the fundamental steps in persona development.”
Scenario 2 Prompt for Task: “Develop a comprehensive step-by-step guide for crafting a persona in user experience design. Illustrate the process with the selection of stock photos from Unsplash.com, emphasizing the creation of the persona on paper. Provide specific guidance on visually representing the persona and its characteristics in a general approach. Recommend a versatile prototyping tool based on general accessibility and popularity. Offer guidance on identifying specific pains and gains using general questions, helping users understand the distinct perspectives between the persona and the designer.”
For the concept, ChatGPT did well describing personas in one paragraph, adding depth to nuances of personas in a second paragraph that gave an example persona, “Alex,” to enhance the readers’ understanding. One researcher remarked, “This is informative, useful, and feels fairly well-written.” Several noted, however, that ChatGPT’s output didn’t follow specifications for one paragraph, instead writing two. We assumed that 250 words was a good length indicator because it was a specific number together with the request for one paragraph. However, we had not considered that LLMs have a known limitation in seeing text through their tokenizers for monetizing purposes, where it may have difficulties in distinguishing between human requests (one paragraph please) and the tokenization process. A token is not the same as a word but can be seen “as pieces of words” equating to roughly four characters: “tokens are not cut up exactly where the words start or end—tokens can include trailing spaces and even sub-words,” white space, punctuation symbols, and more (OpenAI, 2024). In reverse engineering this output, we found the word count for the paragraph was 219 (less than 250 words); but when we used OpenAI’s tokenizer (https://platform.openai.com/tokenizer) to count the tokens, there were 266.
For the task, ChatGPT incorporated many verb-starting sentences that could be used in documentation. It generally followed the prompt in the order given. However, while these lists could be used to begin a step-by-step guide for persona creation, both outputs were too general for actual use. For example, one researcher remarked, “It’s more like a ‘checklist’ than a detailed, step-by-step guide […] it doesn’t even mention research methods for data collection such as conducting interviews, site visits, or think-aloud protocols.” Another stated, “It’s also not a task topic in my opinion just by virtue of being a numbered list of items; I would be unable to operationalize most of this list in any real way after maybe step 3.” Broadly, we felt ChatGPT helped us refine our prompt, giving us confidence it could write a strong answer, but the end-result output was again too broad in scope to be actionable.
Overall, using a self-refining prompt had mixed results. In writing a concept prompt, we had to intervene to simplify the prompt, giving us good results. ChatGPT’s response to the task prompt provided new and unusual ways of creating personas, but the breadth of the answer came at the cost of depth. Once again, while ChatGPT did well with conceptual information, the task prompt output was not in-depth, but rather a high-level bulleted list of actions that was missing necessary information for beginners. We posit that tokenization has a large role in ChatGPT’s output, and our finding of non-compliance with format specifications in a prompt being due to tokenization is an important realization for TPCs.
Scenario 3: Chain-Of-Thought-Prompt Using TPC Experience
The third scenario used chain-of-thought conversational prompting with the expertise of a TPC. One author wrote both prompts and a concrete context with parameters (one paragraph), including output and goal of the information (e.g., a concept in one paragraph; a task in one paragraph) and the context in which we wanted it to write (e.g., cross-use of personas, specific and clear for beginners).
Scenario 3 for Concept: “I am writing user documentation. I am trying to write a clear definition of the concept of user personas in UX that will give people the idea in a nutshell. I am not looking for step-by-step information, just a clear overview in one paragraph. The concept of user persona has to involve getting people to understand that they are not fictional, but archetypes of typical users that are shared in a company context with other designers, product managers, and other technical people. It needs to be simple but specific and clear enough so that a beginner can understand the concept and apply it right away.”
Scenario 3 for Task: “I am writing user documentation. I am trying to write a clear step-by-step process of creating a user persona in UX that will give people the idea in a nutshell. I am not looking for deep conceptual information, just a clear overview in one paragraph with numbered tasks on how to do this as a task. The concept of user persona has to involve getting people to understand that they are not fictional, but archetypes of typical users that are shared in a company context with other designers, product managers, and other technical people. It needs to be simple but specific and clear enough so that a beginner can understand the concept and apply it right away and do it.”
In contrast to the previous scenario, the concept output was written in one paragraph. The output addressed the prompt well, using nuanced language and appropriate definitions. However, one noted that despite telling ChatGPT to address the “not fictional, but archetype” definition of personas, ChatGPT used personas as fictional characters anyway, thus breaking the constraints of the prompt.
For task output, ChatGPT provided action-verb listing headers consisting of “define your purpose,” “conduct user research,” “identify patterns in users,” “create archetypes,” and so forth, with a descriptive 1–2 sentence overview of actions to be taken in each major step. One of us noted that the prompt must have guided ChatGPT to actually produce instructions: “Repeating a task over and over and including step-by-step must have bullied ChatGPT into actually producing a list of steps.” This comment reflects previous prompts not producing adequate step-by-step information (with one researcher remarking that they weren’t convinced that ChatGPT could write step-by-step instructions).
Overall, both prompts resulted in better outcomes for both concept and task information. The concept paragraph was one paragraph as specified and contained appropriate information; the task paragraph was written in an understandable way that used action-verb starting headers and actionable sentences describing what was needed to accomplish the header task. However, one researcher noted that “The bullet list writing of ChatGPT is starting to be somewhat anemic and surface level. What is there is good, but doesn’t tell you completely how to do it, but this is also due to the delimiter of ‘one paragraph.’”
Ultimately, the use of expert-crafted chain-of-thought prompts led to higher scores for HEAT and trust in general. ChatGPT was good at writing conceptual information when given specific length parameters but struggled with task prompts. The chain-of-thought prompting with TPC expertise (human-in-the-loop) seemed to produce the most success with ChatGPT, though we note important limitations in terms of writing with specific length limitations (most likely due to the tokenization process).
Implications and Conclusion
We tested three scenarios representing different strategies for TPC-AI content co-creation. We found that:
- ChatGPT performed well in writing concepts topics, but less so in writing tasks.
- ChatGPT breaks format prompt specifications due to the tokenization process.
- ChatGPT operates well using conversational language at this point, but less so with specific language used by content strategy (DITA, task vs concept topic).
- The HEAT model can be used to make a quick evaluation of how AI-generated content scores on human experience, expertise, accuracy, and trust.
- New models for developing content are emerging, but TPC expertise is still needed.
The implications of these findings are:
- Full content automation is not realistic: ChatGPT has many issues related to recognizing human experience, developing content expertise, or being accurate or trustworthy. Since its tokenization process may allow it to break formatting requests, or confuse formatting requests with topics to write about, TPCs still need to check output.
- AI-generated content still needs to be checked: Our HEAT model was able to help provide a baseline of the quality of output.
- Prompt engineering matters: More research is needed on the impact of different prompting strategies on output quality.
- AI lacks the ability to write in numerical sequences for task topics: Unless overtly prompted, ChatGPT lacks the ability to write structured, actionable numerical tasks with appropriate depth.
- TPC prompt expertise and LLM knowledge yields better results: We got better results when using conversational language and understanding ChatGPT’s underlying assumptions; ChatGPT did worse when asked specifically to use DITA format categories for concept and task topics.
That is, while genAI may be seen by companies to generate automated content more quickly and efficiently, LLMs still require TPCs to write quality prompts and evaluate and modify output. TPCs bring critical expertise skills into the workplace including rich and tacit understanding of different “genres, stakeholders, processes, symbols, and tools;” rhetorical awareness and ability to seek new knowledge while navigating multiple organizational constraints; drawing on multiple semiotic registers (e.g., visual, verbal) to create quality documentation (Schriver, 2012, pp. 304–305). Further, TPCs are subject-matter experts (SMEs) in their work (Mallette & Gehrke, 2018); and while we may be asked to present ourselves differently as “AI content leads,” we think TPCs are ideally positioned to make the above contributions. As we note, incorporating HEAT—human experience, expertise, accuracy, and trust—as a heuristic can help TPCs to both evaluate content and to make a case for their value in AI-generated content to companies. In other words, TPC expertise is still necessary for developing quality prompts, evaluating output, and modifying content to meet diverse user needs. Without expertise to discern between usable and non-usable content, automated genAI-created content has questionable value.
The use of genAI is promising for content development but requires that TPCs assess content critically. Given the difficulties of genAI in addressing various human contexts and inferring dynamic human states, it is important to incorporate a human-in-the-loop perspective that seeks to evaluate and refine AI output. Our HEAT heuristic shows potential for this purpose. It is imperative that genAI feature contextual information as to the quality of content generated. Accuracy scores, user feedback, and notifications to remind users to cross-check information are necessary. The UX of AI, therefore, fosters understanding that genAI output is not the end, but a beginning of writing.
References
Balboni, K., Mullen, M., Whitworth, O., & Holden, H. (2023). The state of user research 2023. User Interviews. https://www.userinterviews.com/state-of-user-research-2023-report
Barker, T. (2021). Looking under the hood: Automated content production. Intercom, 68(6), 46–48.
Bender, E. M., Gebru, T., McMillan-Major, A., & Shmitchell, S. (2021, March). On the dangers of stochastic parrots: Can language models be too big? In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency (pp. 610–623).
Bridgeford, T. (Ed.). (2020). Teaching content management in technical and professional communication. Taylor & Francis and Routledge.
Brundage, M., Avin, S., Wang, J., Belfield, H., Krueger, G., Hadfield, G., … & Anderljung, M. (2020). Toward trustworthy AI development: Mechanisms for supporting verifiable claims. arXiv preprint arXiv:2004.07213.
Borji, A. (2023). A categorical archive of ChatGPT failures. arXiv preprint arXiv:2302.03494.
Christiano, P. F., Leike, J., Brown, T., Martic, M., Legg, S., & Amodei, D. (2017). Deep reinforcement learning from human preferences. Advances in neural information processing systems, 30.
Clark, S. (2017). When to use concept, task, and reference types in DITA. Heretto. https://www.heretto.com/blog/concept-task-reference#concept-topic
Creswell, J. W., & Creswell, J. D. (2018). Research design: Qualitative, quantitative, and mixed methods approaches (5th ed.). Sage.
Csikszentmihalyi, M. (1988). Motivation and creativity: Toward a synthesis of structural and energistic approaches to cognition. New Ideas in Psychology, 6(2), 159–176. https://doi.org/10.1016/0732-118X(88)90001-3
Evia, C. (2018). Creating intelligent content with lightweight DITA. Routledge.
Eloundou, T., Manning, S., Mishkin, P., & Rock, D. (2023). GPTs are GPTs: An early look at the labor market impact potential of large language models. arXiv preprint arXiv:2303.10130.
Duin, A. H., & Pedersen, I. (2021). Writing futures: Collaborative, algorithmic, autonomous. Springer.
Duin, A. H., & Pedersen, I. (2023). Augmentation technologies and artificial intelligence in technical communication: Designing ethical futures. Taylor & Francis.
Fisher, M. Z. (2023). Ask a content icon: Robert Rose on how to use generative AI to your benefit. https://contently.net/2023/08/31/resources/ask-a-content-icon-robert-rose-on-how-to-use-generative-ai-to-your-benefit/
Floridi, L. (2023). AI as agency without intelligence: On ChatGPT, large language models, and other generative models. Philosophy & Technology, 36(1), 15.
Gaube, S., Suresh, H., Raue, M., Merritt, A., Berkowitz, S. J., Lermer, E., Coughlin, J. F., Guttag, J. V., Colak, E., & Ghassemi, M. (2021). Do as AI say: Susceptibility in deployment of clinical decision-aids. NPJ Digital Medicine, 4(1), 1–8. https://doi.org/10.1038/s41746-021-00385-9
Getto, G., Labriola, J., & Ruszkiewicz, S. (Eds.). (2019). Content strategy in technical communication. Taylor & Francis and Routledge.
Getto, G., Labriola, J., & Ruszkiewicz, S. (Eds.). (2023). Content strategy: A how-to guide. Taylor & Francis and Routledge.
Graham, S. S. (2023). Post-process but not post-writing: Large language models and a future for composition pedagogy. Composition Studies, 51(1), 162–168.
Jones, N. N. (2016). The technical communicator as advocate: Integrating a social justice approach in technical communication. Journal of Technical Writing and Communication, 46(3), 342–361. https://doi.org/10.1177/0047281616639472
Kim, A., Yang, M., & Zhang, J. (2020). When algorithms err: Differential impact of early vs. late errors on users’ reliance on algorithms (SSRN Scholarly Paper ID 3691575). Social Science Research Network. https://doi.org/10.2139/ssrn.3691575
Knowles, A. M. (2024). Machine-in-the-loop writing: Optimizing the rhetorical load. Computers and Composition, 71(1). https://doi.org/10.1016/j.compcom.2024.102826
Koo, T. K., & Li, M. Y. (2016). A guideline of selecting and reporting intraclass correlation coefficients for reliability research. Journal of Chiropractic Medicine, 15(2), 155–163. https://doi.org/10.1016/j.jcm.2016.02.012
Lin, S., Hilton, J., & Evans, O. (2021). Truthfulqa: Measuring how models mimic human falsehoods. arXiv preprint arXiv:2109.07958.
Louw, E. (2024). Anatomy of AI prompt. ChatGPT Experts [Facebook page]. https://www.facebook.com/groups/aicomunity/
Mallette, J. C., & Gehrke, M. (2019). Theory to practice: Negotiating expertise for new technical communicators. Communication Design Quarterly Review, 6(3), 74–83.
Milmo, D., & Wearden, G. (2023). AI blunders like Google chatbot’s will cause trouble for more firms, say experts. https://www.theguardian.com/technology/2023/feb/09/ai-blunders-google-chatbot-chatgpt-cause-trouble-more-firms
Noble, S. U. (2018). Algorithms of oppression. New York University Press.
Nielsen, J. (2023). ChatGPT lifts business professionals’ productivity and improves work quality. Nielsen Norman Group. https://www.nngroup.com/articles/chatgpt-productivity/#:~:text=8,ChatGPT%20Lifts%20Business%20Professionals’%20Productivity%20and%20Improves%20Work%20Quality,while%20rated%20quality%20improved%20substantially
Noy, S., & Zhang, W. (2023). Experimental evidence on the productivity effects of generative artificial intelligence. http://dx.doi.org/10.2139/ssrn.4375283
OpenAI. (2024). What are tokens and how to count them. https://help.openai.com/en/articles/4936856-what-are-tokens-and-how-to-count-them
Passi, S., & Vorvoreanu, M. (2022). Overreliance on AI literature review. Microsoft Research.
Price, E. (2024). Air Canada Must Honor a Fake Refund Policy Created by Its Chatbot, Court Says. https://www.pcmag.com/news/air-canada-must-honor-a-fake-refund-policy-created-by-its-chatbot-court
Rose, E. J., & Walton, R. (2018). Factors to actors: Implications of posthumanism for social justice work. In K. Moore, & D. Richards (Eds.), Posthuman praxis in technical communication (pp. 91–117). Routledge.
Schriver, K. (2012). What we need to know about expertise in professional communication. In V. W. Berninger (Ed.), Past, present, and future contributions of cognitive writing research to cognitive psychology (pp. 275–312). Psychology Press.
Shumailov, I., Shumaylov, Z., Zhao, Y., Gal, Y., Papernot, N., & Anderson, R. (2023). The curse of recursion: Training on generated data makes models forget. arXiv preprint arXiv:2305.17493.
Springer, A., Hollis, V., & Whittaker, S. (2017, March 20). Dice in the black box: User experiences with an inscrutable algorithm. 2017 AAAI Spring Symposium Series. 2017 AAAI Spring Symposium Series. https://cdn.aaai.org/ocs/15372/15372-68262-1-PB.pdf
Springer, A., & Whittaker, S. (2020). Progressive disclosure: When, why, and how do users want algorithmic transparency information? ACM Transactions on Interactive Intelligent Systems (TiiS), 10(4), 1–32.
Tham, J., Howard, T., & Verhulsdonck, G. (2022). Extending design thinking, content strategy, and artificial intelligence into technical communication and user experience design programs: Further pedagogical implications. Journal of Technical Writing and Communication, 52(4), 428–459. https://doi.org/10.1177/00472816211072533
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M. A., Lacroix, T., … & Lample, G. (2023). Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971.
Verhulsdonck, G., Howard, T., & Tham, J. (2021). Investigating the impact of design thinking, content strategy, and artificial intelligence: A “streams” approach for technical communication and user experience. Journal of Technical Writing and Communication, 51(4), 468–492. https://doi.org/10.1177/00472816211041951
Vinchon, F., Lubart, T., Bartolotta, S., Gironnay, V., Botella, M., Bourgeois-Bougrine, S., … & Gaggioli, A. (2023). Artificial intelligence & creativity: A manifesto for collaboration. The Journal of Creative Behavior, 57(4), 472–484. https://doi.org/10.1002/jocb.597
Wang, B., Min, S., Deng, X., Shen, J., Wu, Y., Zettlemoyer, L., & Sun, H. (2022). Towards understanding chain-of-thought prompting: An empirical study of what matters. arXiv preprint arXiv:2212.10001.
Wang, G. (2019). Humans in the loop: The design of interactive AI systems. https://hai.stanford.edu/news/humans-loop-design-interactive-ai-systems
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., … & Zhou, D. (2022). Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35, 24824–24837.
Wei, J., Bosma, M., Zhao, V. Y., Guu, K., Yu, A. W., Lester, B., … & Le, Q. V. (2021). Finetuned language models are zero-shot learners. arXiv preprint arXiv:2109.01652.
World Economic Forum. (2022). A blueprint for equity and inclusion for artificial intelligence. https://www3.weforum.org/docs/WEF_A_Blueprint_for_Equity_and_Inclusion_in_Artificial_Intelligence_2022.pdf
About the Authors
Dr. Gustav Verhulsdonck is an associate professor in the Business Information Systems department at Central Michigan University. Prior, he worked at IBM as a technical writer. He also consulted for clients such as NASA and the US Army. His research interests are user experience design, data analytics, and how technologies impact communication practices. He is co-author of UX Writing: Designing User-Centered Content (Routledge, 2023) together with Dr. Jason Tham and Dr. Tharon Howard.
Dr. Jennifer L. Weible is a professor and director of the Doctor of Educational Technology program at Central Michigan University, and previously worked in K-12 education as a chemistry/physics teacher and technology integrator. Jennifer is a learning scientist who explores science curiosity, STEM/STEAM informal learning, creativity, science practices, and technology-supported learning environments.
Dr. Danielle Mollie Stambler is an assistant professor in the Department of Writing, Rhetoric, and Technical Communication at James Madison University. She studies the rhetoric of health and medicine, technical communication and user experience, and disability rhetoric, along with collaborating in the Building Digital Literacy cluster at the Digital Life Institute. Her work has been published in a number of journals including Communication Design Quarterly, Technical Communication Quarterly, Journal of Technical Writing and Communication, and Rhetoric of Health and Medicine.
Dr. Tharon W. Howard served as the graduate program director of the Master of Arts in Professional Communication program and teaches in the Rhetorics, Communication, and Information Design doctoral program at Clemson University. He received the STC’s J.R. Gould Award for Excellence in Teaching Technical Communication and the Rainey Award for Excellence in Research. As Director of the Clemson University Usability Testing Facility, he conducts sponsored research aimed at improving and creating new software interfaces, online document designs, and information architectures for clients including Pearson Higher Education, IBM, NCR Corp., and AT&T. For his work promoting usability and UX design in TPC, Tharon was awarded the Usability Professionals Association’s “Extraordinary Service Award.” Howard is the author of five books including UX Writing: Designing User-Centered Content in which he and his co-authors, Jason Tham and Gustav Verhulsdonck, explore—among other topics—a user-centered approach to generating content with AI.
Dr. Jason Tham is an Associate Professor of Technical Communication and Rhetoric at Texas Tech University and Assistant Chair of the Department of English. His current research interests are design thinking approaches in technical communication pedagogy and practices.
