Mats S. E. Broberg, FLIR Systems
Abstract
Purpose: This study describes the specification, development, procurement, and implementation of two systems for managing business-critical technical data for a large multinational company.
Method: This study uses a descriptive analytical method, based on available project data, interviews, and fault analyses.
Results: The results of this research outline the technical, strategic, and organizational aspects that are associated with the development and procurement of two business-critical systems managing large publishing volumes, a variety of formats, and fast deployment of outputs.
Conclusion: A system and function analysis of all products was critical for success; a high degree of terminological quality was of paramount importance; consistent writing and typesetting rules were required to maximize 100% repetitions in the localization workflow; and a strong content management system (CMS) infrastructure was a defining factor for the second procurement and implementation.
Keywords: XML (EXtensible Markup Language), technical data, procurement, implementation, content management system
Practitioner’s Takeaway:
- Considerable resources need to be spent on functional and linguistic product analyses to create and optimize the content data model. This step is crucial.
- Product relationships, hierarchies, dependencies, and release management functions relating to the Enterprise Resource Planning (ERP) system are preferably handled by a relational database while letting the CMS handle technical data content for integration into standard publishing and localization workflows.
- Adopting task-based reporting frameworks and high-volume formatting engines opens up vast possibilities for tailoring the output to various recipients and stakeholders.
This case study describes a large multinational manufacturing company’s processes and tool chains for the management and publication of critical technical data, i.e., specifications of thermal cameras and their associated accessories. The article provides information about the analysis of the business and technical needs, development and implementation of the two systems (an internally developed database and a commercially developed module to an existing XML-based system for product information), and their formatting and publishing strategies.
Introduction
FLIR Systems, Inc. (NASDAQ: FLIR) was established in 1978 and is headquartered in Wilsonville, Oregon, USA. With manufacturing and R&D facilities in the US, Europe, and Middle East, it is a world leader in the design, manufacturing, and marketing of sensor systems that enhance perception and awareness. Pioneers in the private and public infrared industries, FLIR provides advanced thermal imaging and threat-detection systems for use by industry, consumers, science, law enforcement, and the military for a wide range of imaging, thermography, and security applications.
The acquisition of Agema (Sweden) in 1998 and of Inframetrics (Boston, USA) in mid-1999 provided FLIR engineering teams and sales and support infrastructure that accelerated FLIR’s success in commercial thermal imaging markets.
I was employed at FLIR Systems’ Swedish site, formerly Agema, in 1999 to manage the production of end-user documentation for infrared cameras and image-analysis programs, as well as the procurement and coordination of translations. At that time, the product portfolio was limited and production volumes were relatively small.
FLIR’s revenue in 2002 was 261 million USD. Since then, the company has expanded greatly, both through a large number of acquisitions of other companies in related industries (16 acquisitions since 2007) and through the strategic identification of new applications, customer groups, and industrial segments. For 2016, the revenue was 1.66 billion USD.
Technical background
Since 2002, all client documentation within the Swedish part of the Instruments division has been created and maintained in XML-based documentation systems. Adopting XML as a best practice was a direct consequence of the ever-increasing volume of documentation and localization that was, and still is, the global responsibility of the Swedish site for their products.
The first system, which was specifically procured for the Swedish site, was in operation between 2002 and 2012 (Broberg, 2004), whereas the second system was commissioned in 2010 and is now used at several geographical sites and business units within the FLIR group (Broberg, 2016).
Up until 2006, technical data for the products were maintained as part of the user documentation and within the documentation system in which it was created. With the limited product portfolio that existed at the time, this was a solution that worked—the volume of technical data was not particularly extensive, so it could be managed in the established documentation workflow in a professional manner.
Toward the end of 2006, we made the decision to separate the work of creating and maintaining technical data from the standard documentation work. This decision was based on the fact that the products being created were becoming more and more complex and, consequently, the data were becoming more and more time-consuming to maintain in the documentation workflow that was being used for user documentation. Another significant fact was that the volume and type of technical data that would be created, documented, and maintained for new generations of products required an entirely new approach. For an optimum data structure we could use across the product range and throughout the product life cycle, we wanted to create a new content data model. We also wanted to find a cost-effective solution and efficient formatting workflows.
The task of creating a new content data model was large and was carried out by one of the company’s former software managers. This work involved things like:
- System and function analysis of all products in the existing product portfolio, with benchmarking against products of other FLIR divisions
- Concept analysis of existing language usage and terminological alignment of expressions
- Definition of orthographic and typographic guidelines
- Relationship analysis of products in order to identify technical compatibility
- Documentation of processes and methods to ensure repeatability
Based on the new content data model, the library of technical data was built in Microsoft Excel, which offered the powerful formula and filter functionality. As one person assembled the technical data, a very high level of data quality could also be maintained. Data were regularly imported from Microsoft Excel to SalesWeb/PPS (Price Preparation System)—a pre-existing internal database for release, article, and pricing management that was developed in-house by FLIR. With further development of SalesWeb/PPS, Microsoft Excel was abandoned as a data source in 2008, and creation and maintenance of technical data could thereafter be carried out entirely in SalesWeb/PPS. The number of data points during this transition was approximately 15,000 and, two years later, it had grown to approximately 100,000.
Between 2006 and 2010, technical data were exported from SalesWeb/PPS as article number files in XML, in accordance with the DTD (Document Type Definition) that was used in the documentation system (flex.dtd). These files were then integrated into corresponding documentation in the documentation system and published as part of the PDFs (Portable Document Format).
Development of the First Technical Data System
During 2008, intense discussions took place about how we could find a successful technical solution for publishing technical data in several different formats for sales teams, distributors, and end clients. A critical point in these discussions was speed, as we wanted the option of being able to correct any possible errors in our technical data at short notice and to be able to republish updated data sheets on our client support site as quickly as possible. Another issue was related to various options for other departments and sites within the group being able to reuse our technical data in different ways (e.g., in marketing material and quotations). We also wanted to look into the possibilities of creating a product catalog of our products and accessories, which could be automatically kept up to date at the same pace as the individual data sheets.
Toward the end of 2008, we invited a number of Swedish and foreign companies to quote their systems to us in order to study in more detail what options they were able offer for the challenges we were facing. The difference between the various solutions was fairly large, with regard to both functionality and price. Some solutions were more oriented toward maintaining spare parts structures for the automotive and other heavy industries, whereas others either stood out as special development projects for FLIR or as complete and highly suitable products. At this stage, no decisions were made to move forward with any of the systems on offer. Certainly, most offered a significantly more powerful framework than the one we had (e.g., with regard to speed and number of outputs), but none of them offered the dynamic advantages and toolbox of functions that had been developed in Sales Web/PPS between 2006 and 2008.
At this point, we began, instead, to take a closer look at the various formatting engines that were available on the market and had been around for a while. These were and are used for formatting in, for example, the following industrial segments:
- Aerospace and defense
- Heavy industries
- Standards and regulatory
- Yellow Pages/White Pages directories
- Legal and legislative
The advantages of these types of formatting engines are that they are used to format large volumes of data at a high speed and with great reliability. Constant formatting 24 hours a day, 7 days a week, 365 days a year is not unusual in these contexts and within these segments. In that respect, the engines are well tested and usually very stable in their technical processes and functions. Our technical analysis indicated that this type of formatting engine could work well for our needs. There were a number of different formatting engines on the market at that time that could have been suitable, such as the following commercial solutions:
- XEP from RenderX (which was already integrated as a formatting module in our documentation system)
- AH Formatter from AntennaHouse
- OASYS from Miles 33
- XPP from XyVision (now SDL XPP)
- Arbortext 3B2 from Arbortext (now PTC APP)
- DSSSLprint and NextPublisher from Next Solution
- TopLeaf XML Publisher from Turn-Key Systems
- DL Pager/DL Composer from Datalogics
- Life*TYPE from Corena
- Miramo from DataZone
- Patternstream from Finite Matters
There were also a number of open-source solutions that could have been interesting, including FOP from Apache Software Foundation. We also looked into the options of using various text processors (e.g., TeX/LaTeX, troff/groff, or lout) as the back end in an XML workflow.
In addition to these engines, we also looked more closely at various types of on-demand solutions, where formatting to PDF is done in run time when a client, for example, clicks on a link for a certain technical data sheet.
After a technical review and cost-benefit analysis of a number of engines, we eventually decided to bring in TopLeaf XML Publisher from the Australian company Turn-Key Systems (http://www.turnkey.com.au). Turn-Key Systems is a small software company with four employees based in Sydney and has been developing software for formatting purposes since 1971. During the 1970s and 1980s, the company was one of the global industry leaders for the automatic formatting of Yellow Pages and Whites Pages directories, and their software was used to typeset 50% of Australia’s phone directories for a period of 20 years. At the time of our purchase decision, in the spring of 2010, their TopLeaf product was relatively unknown to a wider audience in Europe and the USA, and during the development and commissioning of our formatting framework, it would emerge that the product was a very stable, fast, and reliable formatting engine for a competitive price. When it comes to technical functions and options, it stands up quite well against other formatting engines that cost several times as much.
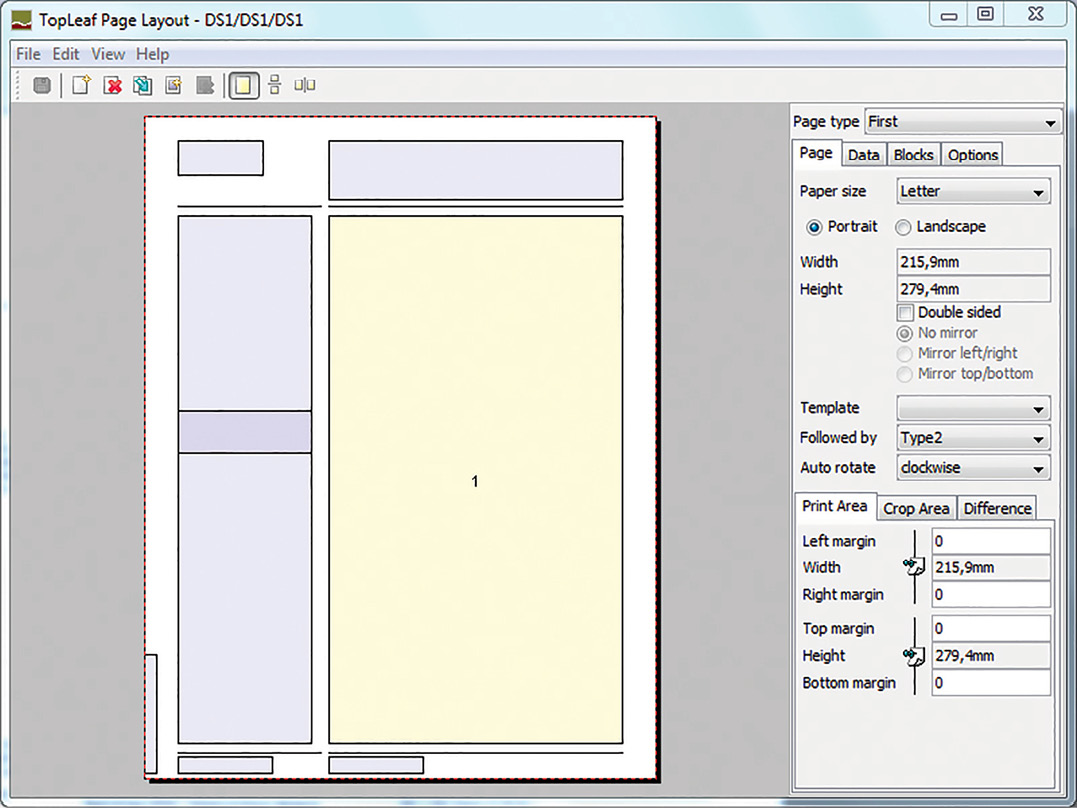
TopLeaf has an intuitive graphical interface for building up grid-based layouts and mapping various elements of input data workflow with the character and paragraph styles created in the program. Elements can also be mapped to different blocks in the layout that are developing. PDFs from external sources can also be included in the formatting chain, which was used to a great extent when it came to the mechanical drawings from our CAD (Computer-Aided Design) systems.
For our own needs, we developed eight different style sheets in total for PDFs—two for product catalogs in A4 and US Letter, and five for separate data sheets in A4 and US Letter page sizes, the latter with different types of regionalized information (e.g., contact details of local sales offices).
A detailed description of TopLeaf is outside the scope of this article, and readers wanting to know more are referred instead to the documentation that accompanies the evaluation version of the software. Figure 1 displays an example of what the user interface looks like.
The technical workflow that we built up with SalesWeb/PPS and TopLeaf and which was in operation between the autumn of 2010 and the summer of 2014 was as follows, where all of the stages were completely automated and ran every night:
- Exporting of technical data from SalesWeb/PPS as XML files (DocBook 4.5) to a specific server.
- Copying the XML files to a formatting server.
- Running a number of batch scripts in order to create the formatting script that would control TopLeaf’s formatting for data sheets and product catalogs.
- Beginning formatting. Data sheets were formatted in two-pass formatting and the product catalogs in three-pass formatting.1
- Feedback reporting of the processes via log files.
- Running a number of batch scripts in order to optimize the PDF files in different ways (e.g., setting certain attributes and downsampling of images).
- Copying the PDF files to SalesWeb/PPS.
- Deleting the formatting server’s XML and PDF files.
- Starting up an FTP (File Transfer Protocol) client for uploading catalogs and data sheets to FLIR’s external support site.
- Feedback reporting of the processes via log files.
In critical cases where a correction of technical data must be published externally or internally faster than within 24 hours—which was the standard formatting periodicity—this production chain could be initiated manually, which cut the time from correction in SalesWeb/PPS to an updated specification on our client support site to 5–10 minutes.
As mentioned previously, TopLeaf is a stable formatting engine. During the four years that this engine was in operation in the first technical data system, it formatted approximately 10 million PDF pages a year and was as stable when formatting a large number of individual data sheets (with a scope of 5–30 pages each) as when formatting the extensive product catalogs (with a scope of 3000–4000 pages each).
In recent years, TopLeaf has received a great deal of exposure on the European and American markets. Today, it is available as a plugin for common editing tools, like Oxygen Author and Editor from Syncro Soft and XMetal from Just Systems, which provide users who are unfamiliar with XSLT (EXtensible Stylesheet Language Transformation) programming the opportunity to develop complex templates and formatting workflows.
Development of the Second Technical Data System
As mentioned, we initially procured a new XML-based documentation system in 2009, and we began to put it into operation in the Swedish part of ITC (Infrared Training Center, a business unit within FLIR) and GSS (Governmental Systems Sweden, a division that develops fixed surveillance systems, vehicle vision systems, and thermal weapons sights) in 2010 and 2011, respectively.
In 2012, this system also replaced the previous system (used since 2002) for the production of user documentation within the Instruments division, and this provided an opportunity to evaluate the options available for extending the new system in order to also be able to maintain and publish technical data.
Despite SalesWeb/PPS originally not having been developed to function as a data source for technical data, the solution had worked well for 4 years. There were, however, a number of aspects that were problematic and that had to be resolved if we were to be well equipped for future challenges.
We identified the following main disadvantages:
- No machine-powered version management: Version numbers were entered manually and version assurance, therefore, became individual-bound rather than machine-defined.
- No capacity for version comparisons: As SalesWeb/PPS only kept the latest version of technical data, two historic versions of technical product data could not be compared.
- No mandatory editing history: As the system lacked a commit concept, the relevant writer had to manually enter a description of the changes into an administration form and specify which version had been changed.
- No infrastructure for the translation workflow: SalesWeb/PPS was primarily a release, article, and pricing management system and not originally built in the necessary way should the translation of technical data be required.
Another problem was related to the workflow of technical data, as the system solution with SalesWeb/PPS and TopLeaf had, over time, been developed into a formatting workflow that ran parallel to the formatting workflow for the user documentation, rather than the two of them being parallel and integrated. This was seen as problematic and was one of the things we wanted to improve. Our ambition was to be able to publish the technical data both as separate publications per product and as chapters in the user documentation, and that special formatting conditions could automatically be implemented depending on the prevailing context. We also wanted the option of working with XML markup in the technical data (e.g., for variables, modularizing, and rendering), which the existing solution could not offer.
There were also several weighty benefits to using SalesWeb/PPS, for example:
- Link to FLIR’s ERP system
- Release management of articles
- Relational connection between articles (i.e., technical compatibility)
After an evaluation of the pros and cons of SalesWeb/PPS as a technical data source, we decided that it would be the wrong route to take to further develop the system to meet the new demands we had to set. At the same time, we wanted to take advantage of the powerful release management functions and the relational database, which we did not feel would be necessary to replicate in a new system for technical data. When it came to the formatting framework, we could also see a number of improvement opportunities, as we would want to publish to significantly more output formats in the future than we had done previously (e.g., Microsoft Word and Microsoft Excel) as well as complete HTML (HyperText Markup Language) and XML packages for our distributors’ websites.
We decided to separate the function and production responsibilities between SalesWeb/PPS and the documentation system that had been put into operation within the Instrument division and retained the following elements of SalesWeb/PPS:
- Technical release management of articles internally and externally—and thereby release management of output data from the documentation system
- Portal structure with product links to output data from the documentation system
- Generation of relational article lists in XML as input data to the documentation system’s formatting framework (technical compatibility between products)
- Certain optical data as input data to FLIR’s online FOV (Field of View) calculator
A brief technical overview of the documentation system is given here before the specially developed module for technical data is described in detail.
Simonsoft (http://www.simonsoft.se), a Gothenburg-based company with 10 employees, is a wholly-owned subsidiary of the PDS Vision Group (http://www.pdsvision.com). It supplies products and services in the PLM field, mainly from the American company PTC (http://www.ptc.com). The company was founded by a number of people who broke away from PTC in connection with the acquisition of Arbortext in 2005 and has since been the sole distributor of the products on the northern European market. Today, the company also has a presence in England and Germany, as well as retailers in Canada. Simonsoft also offers solutions with varying levels of integration, based on PTC products, and it was one of these that was submitted in the tender to FLIR in 2007.
This system covers a number of well-known and tried-and-tested modules and software that are integrated and packaged into a comprehensive solution to create and maintain technical information throughout its life cycle.
This system is based on the following modules and software:
- The editing tool Arbortext Editor from PTC. This editing tool for SGML (Standard Generalized Markup Language) and XML was introduced in 1991 under the name of Adept Editor by Arbortext in Ann Arbor, Michigan, USA, and is one of the most widespread and widely used editing tools. Arbortext was acquired by PTC in 2005.
- The Simonsoft CMS version-management system, based on Subversion from Apache Software Foundation. Subversion, an open-source program for version management, was released in 2000 and has several hundred thousand installations globally. Simonsoft CMS also contains a Web interface for Subversion and has been designed to cater to a fully Web-based management and overview of all files in the version-management system.
- The Advanced Print Publisher formatting engine from PTC. This formatting engine, one of the most advanced engines on the market, was previously known as Advent 3B2 and was developed originally by Advent Publishing Systems in England. The company was acquired by Arbortext in 2004.
- Arbortext Styler from PTC. Arbortext Styler is an advanced tool for developing and maintaining style sheets for FOSI (Formatting Output Specification Instance), XSLT, and the proprietary style-sheet language for the Advanced Print Publisher formatting engine.
Simonsoft’s solution is fully cloud-based and can be accessed over an https:// connection from any geographic location and computer, provided the computer has the necessary security certificates installed.
Simonsoft Batch Publishing
The module that was developed for us to manage technical data is called Simonsoft Batch Publishing and is an add-on service to Simonsoft CMS with which you create formatting jobs that are scheduled or are started manually.
Simonsoft Batch Publishing uses the Simonsoft CMS reporting framework to which you can send various requests that provide input about what is to be published. This means you can, for example, schedule a formatting job that every evening asks the Simonsoft CMS what has been updated by a certain type of document.
The reporting framework can provide specific information from the Simonsoft CMS. This includes which documents another document is used in or extracting documents which have been released but do not have translations. In addition to using it for batch formatting, the reporting framework is also used to create reports that can, for example, give the administrators or authors a better insight into their documentation work.
The results of formatting can be reprocessed if necessary, for example, by running XSLT transformations or by converting the results to yet another format (e.g., *.csv to *.xls). Usually, graphics and other files are repackaged into zipped packages or the results are forwarded to a Web server or other type of recipient.
Formatting jobs are scheduled via a Cron-like syntax, which enables advanced schedules to be created. As well as scheduling a time, date, weekday, etc., you can create dependencies between formatting jobs. When one job is complete, another or several other formatting jobs can begin. You can even send parameters between them, for example, to add a dynamic input value to a subsequent job.
You can also instruct Simonsoft Batch Publishing to initiate formatting jobs via a third party.
The actual formatting jobs can be configured to basically carry out any kind of manoeuver necessary—everything from requesting a report from the Simonsoft CMS and publishing with the Arbortext Publishing Engine, to moving, unzipping, zipping, deleting, or running XSLT transformations on the formatted result.
Architecturally, Simonsoft Batch Publishing is an independent server, which in turn communicates with the Simonsoft CMS, also an independent server, and the formatting server (in this case an Arbortext Publishing Engine). A formatting task uses the reporting framework and publishes the results of one or more report requests to the Simonsoft CMS with the help of the Arbortext Publishing Engine. The task manages the results from the Arbortext Publishing Engine, and when the reprocessing is complete, the formatting task is also complete.
All formatting tasks are logged, which means that if anything goes wrong, you can subsequently troubleshoot and almost immediately locate where the error began. In the event of formatting errors, an email can also be sent to appropriate recipients.
Simonsoft Batch Publishing currently carries out an analysis of necessary formatting needs every night. This analysis determines which technical data have been updated and which other documents contain these data. Formatting is then carried out, when it comes to separate data sheets, in the following formats:
- PDF, A4 (see Figure 2)
- PDF, US Letter
- Microsoft Word
- Microsoft Excel
- XML
- XML as complete package with images (*.zip)
- HTML
- HTML as complete package with images (*.zip)
Depending on whether technical data have been updated, 78 product catalogs—ranging from approx. 200 to 3,500 pages—are also automatically published, usually every night (see Figure 3). For this task, TopLeaf was kept as a stand-alone formatting engine and works parallel and external to the Simonsoft Batch Publishing workflow.
The results of the formatting job are then moved to a secure FTP site, from which the files are downloaded to an internal server at FLIR. On this server, a number of batch operations and scripts are run and the files are then deployed internally on SalesWeb/PPS and externally on FLIR’s client support site (http://support.flir.com, see Figure 4). The main files are HTML files that are then linked to other output data formats. The XML files are exported to an external database and read into a DataTable on the Web server in order to run a product data comparison engine.
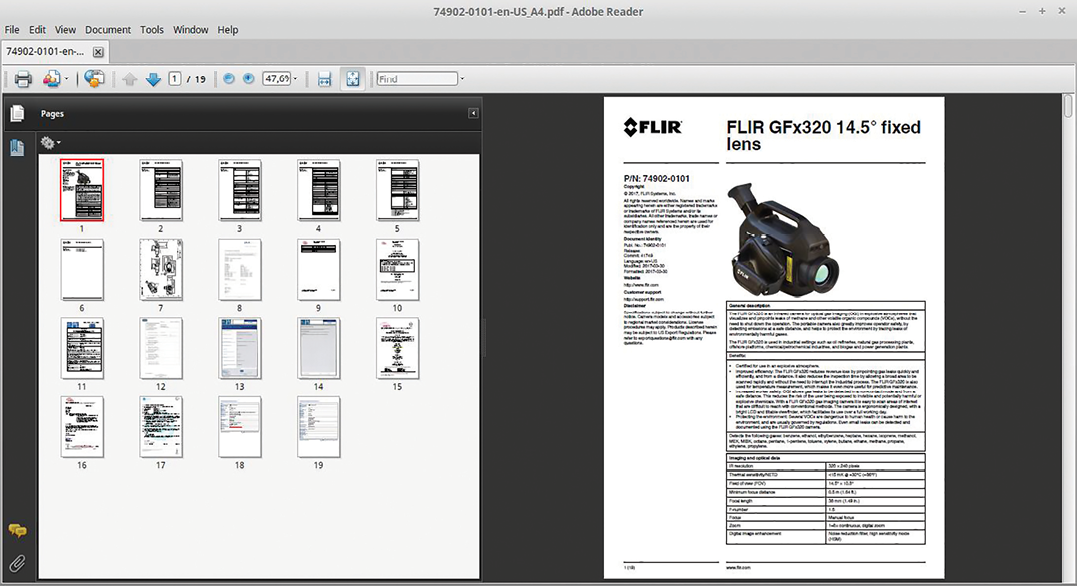
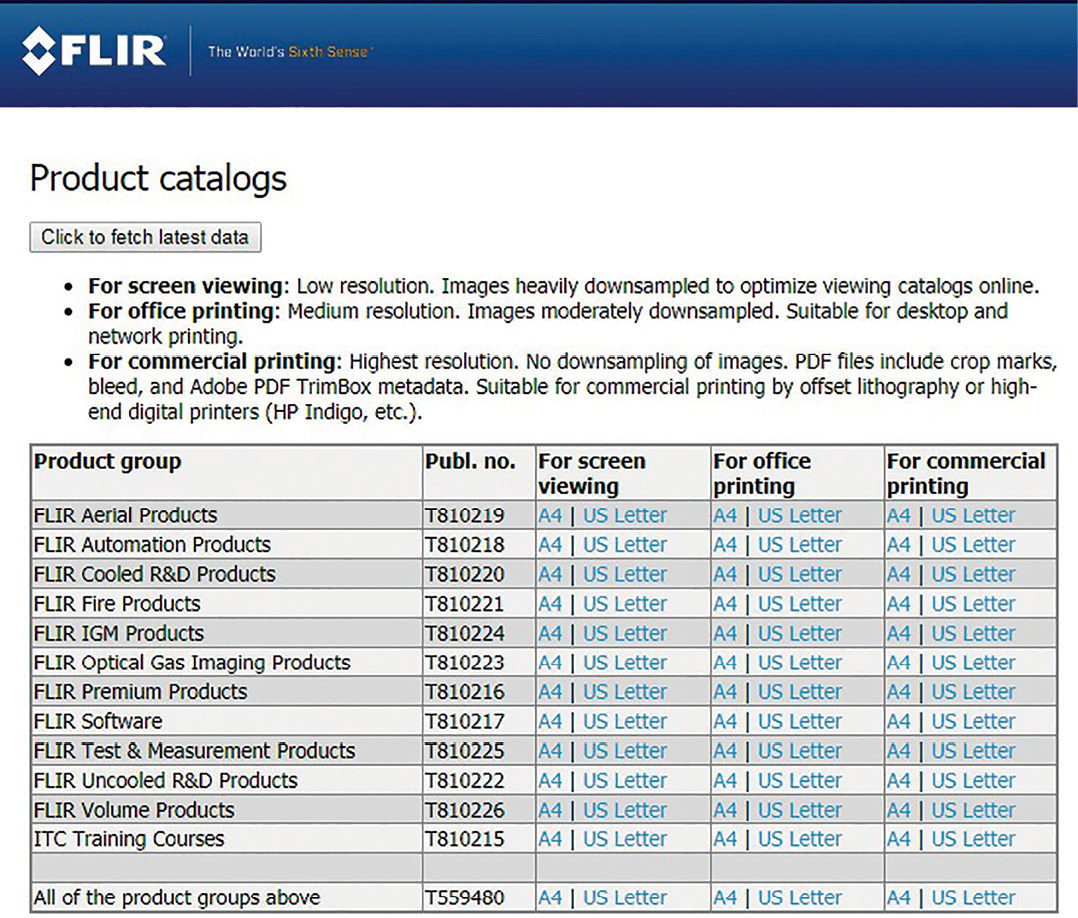
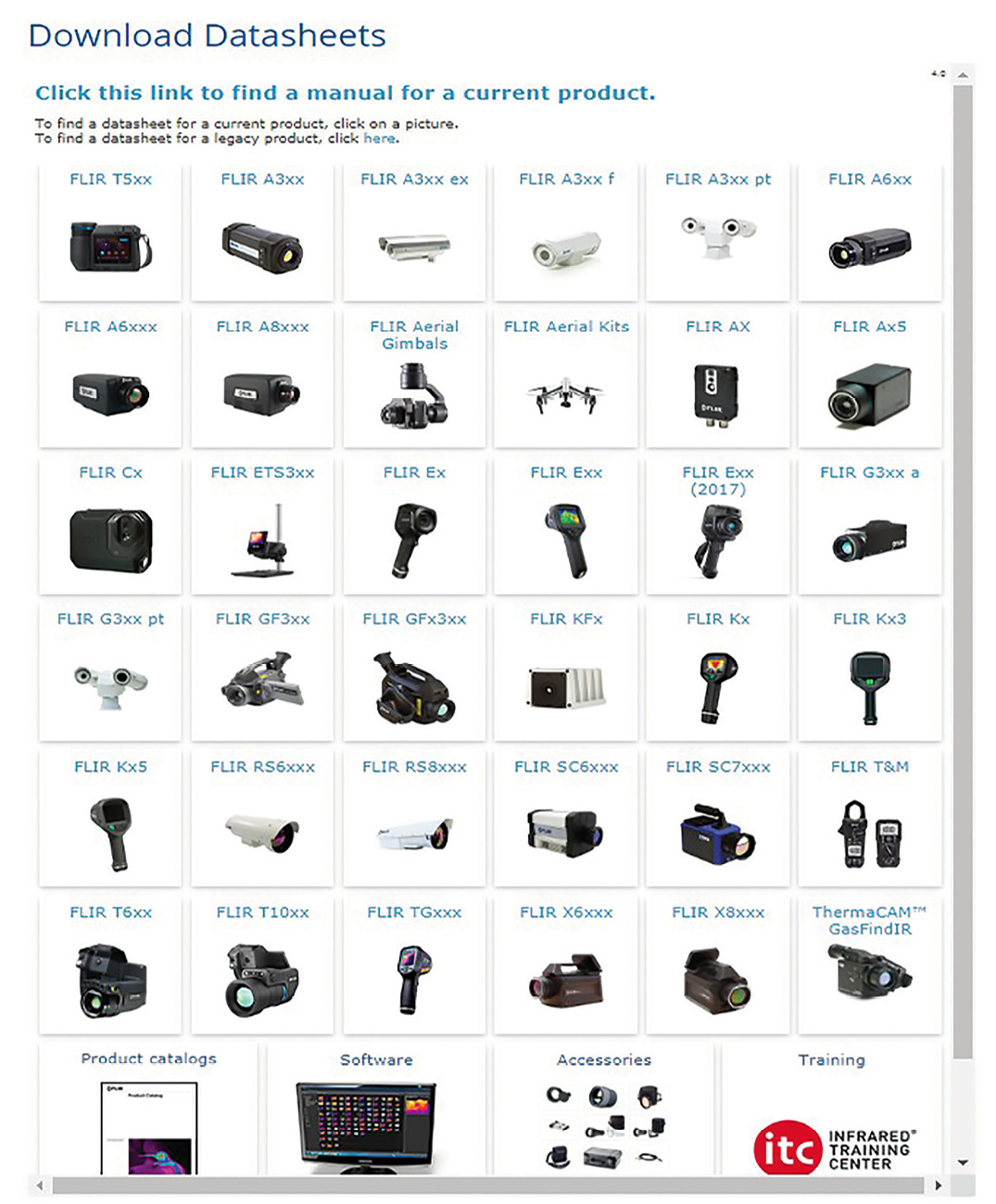
Customers can also aggregate their own technical data and download the data as *.csv files for further analysis and post-processing in Microsoft Excel (see Figure 5). This is a clear customer benefit, since customer (and distributor) needs vary considerably. This function leverages on the product data comparison engine.
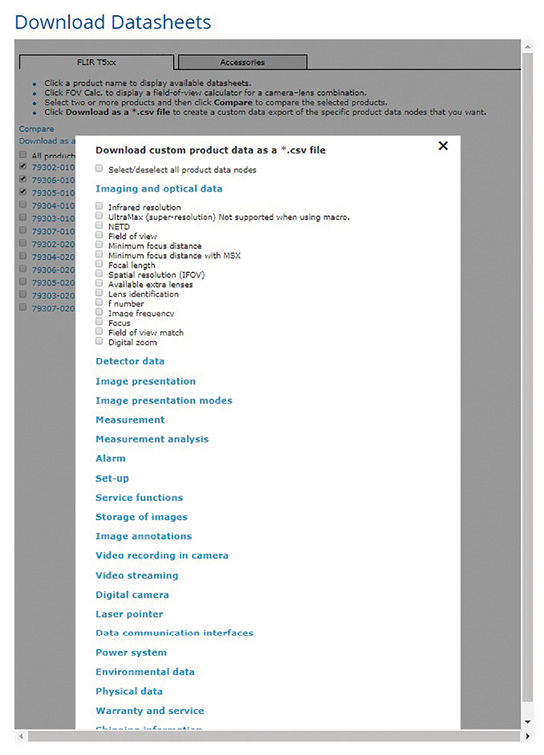
As was the case with SalesWeb/PPS and TopLeaf, a formatting job can be initiated manually if a critical correction must be deployed within a short period of time (<5 minutes).
Folder structure for technical data in the Simonsoft CMS
As there is a need to allow Simonsoft Batch Publishing to report and act on technical data specifically, then these data are kept separated from other technical documentation in the Simonsoft CMS. They are, however, part of a large number of technical publications in the form of including links (XInclude). There are also other reasons why we have chosen to separate the technical data from other documentation—we run a number of scripts and batch operations on XML files in various contexts (e.g., orthographic and typographic quality assurance and correction of possible errors) so we want logical limitations in the directory structure.
The structure for technical data is currently as follows:
- High-resolution product images
- Mid-resolution product images
- Dimensional drawings for PDF inclusion
- External documents for PDF inclusion
- XML files for technical data
- Relational article number lists (generated by SalesWeb/PPS)
Technical benefits
Technical data for approximately 1,500 products are currently maintained in the Simonsoft CMS, and the system offers a number of important technical and strategic benefits compared to maintaining technical data in SalesWeb/PPS:
- CMS with relational information analysis (where-used and dependencies)
- Version management and capacity to compare technical data, temporally or functionally
- Integration of technical data into other publications
- Powerful infrastructure for translation management and capacity for automated translation based on approved past translations in the CMS
- Reporting framework, with identification of revised technical data and generation of automatic formatting tasks
- A framework for formatting a number of different outputs
The Future
After about three years of live operation of the module for technical data, it is our assessment that we have gained a powerful solution, and are well equipped for the future.
In addition, the solution has such a dynamic architecture that it can easily and cost-effectively be modified and further developed for the various types publishing scenarios that may arise.
Such scenarios may include the following:
- Responsive HTML5 output: While our manuals are published in Responsive HTML5 today, the HTML-based technical datasheets are not. This will definitely become a high priority within the near future.
- Additional output formats: Since the technical data system is currently the most up-stream system in the organization, there are a number of downstream information stakeholders and information consumers that could benefit from an easier and more seamless integration of the data in their workflows. Such workflows include, for example, InDesign, and one idea would be to generate partially populated InDesign *.idml documents according to a set template design for further work within local and global marketing departments.
- Automated population of ERP- and R&D-centric data: Today, some pieces of data for the products are maintained in FLIR’s ERP systems and other systems (e.g., JIRA, SharePoint, and Confluence) and are manually entered into the technical data system. As manual work is always a source for error, we are currently looking into how to automate this workflow, either by using an API (Application Programming Interface) or by letting the ERP/R&D systems output data packages that are absorbed in run time during the Simonsoft Batch Publishing tasks.
- A forms-based data entering interface: In the current system, technical data are created and maintained in Arbortext Editor. While this is not a problem for our experienced users and also offers many very powerful features, SMEs (Subject Matter Experts) who have no experience with XML could possibly benefit from a forms-based interface with set menu choices of data. Such interfaces could also support “smart data” (e.g., automatically converting metric to imperial units). We are currently investigating various routes to offer such an interface.
- Aligning data to taxonomical, dictionarial, and transactional product data standards: While there is no standard that solves all global requirements, aligning the product data to some of the more widely used standards and developing associated transactional filters would greatly benefit downstream stakeholders in distribution and e-commerce. Such standards include eCl@ass, ETIM, eOTD, RosettaNet, etc.
Glossary
Formatting engine: A computer program that, with no user interaction, typesets and formats input data according to a set of predefined rules.
Content data model: In this context, a master technical data template that contains the minimum number of data points to describe all products.
Orthographic and typographic guidelines: A set of rules of how text shall be written with regards to the use of proper glyphs. Examples include the use of em dashes instead of hyphens for parenthetical expressions, the proper use of curly quotation marks instead of straight quotation marks, true multiplication signs instead of the letter x, etc.
System and function analysis: The analysis of a product in order to reach the optimum number of information nodes to describe that product from a technical data point of view.
Terminological alignment of expressions: The process of investigating and deciding which terms to use for a function or feature and to screen existing content for non-approved term variants.
Tool chain: In this context, the chain of various computer programs, batch operations, and scripts used for a publication scenario.
Endnotes
- When using formatting engines that generate external table of contents or index files that will be re-read by the formatting engine for inclusion in the formatting stream, two or three formatting passes are necessary to resolve pagination and cross-references. This is due to the fact that the engine cannot estimate how many pages the table of contents or index will need and, therefore, can neither resolve the cross-references using only one formatting pass
References
Broberg, M. (2004). A successful documentation management system using XML. Technical Communication, 51, 537–546.
Broberg, M. (2016). A decade of XML—and a new procurement and lessons learned. Technical Communication, 63, 6–22.
About the Author
Mats S. E. Broberg was, up until October 2017, Technical Documentation Manager at FLIR Systems, a global leader in civil and military infrared cameras and image-analysis software. He worked at FLIR Systems since 1999 and was responsible for several procurements of XML-based documentation management systems and automated formatting toolchains. He is currently Service Information Manager at Getinge. He is available at mats.broberg@gmail.com.
Manuscript received 24 August 2016, revised 2 April 2017; accepted 5 April 2017.
